Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the UT Libraries Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of, and future creative contributions to, the growing fields of digital scholarship.
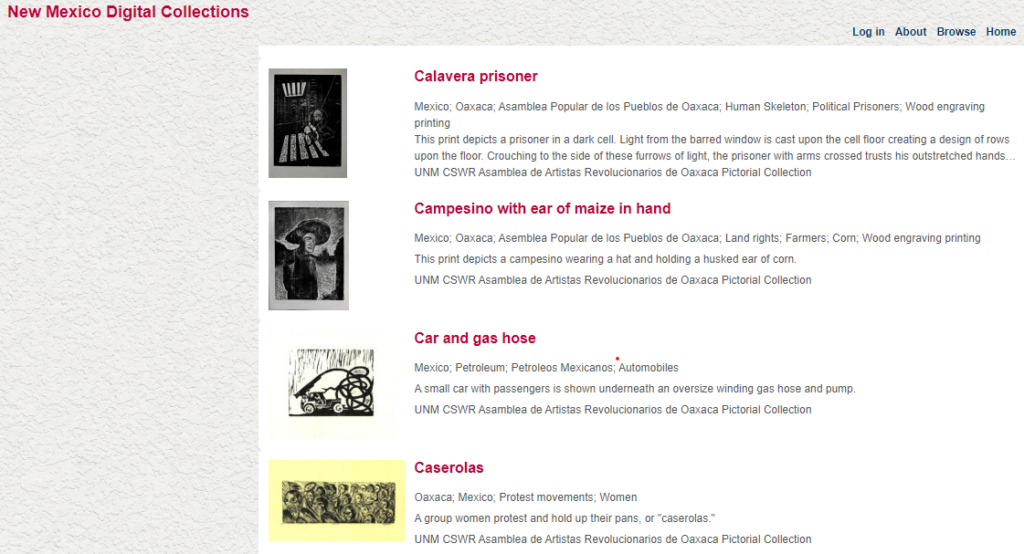
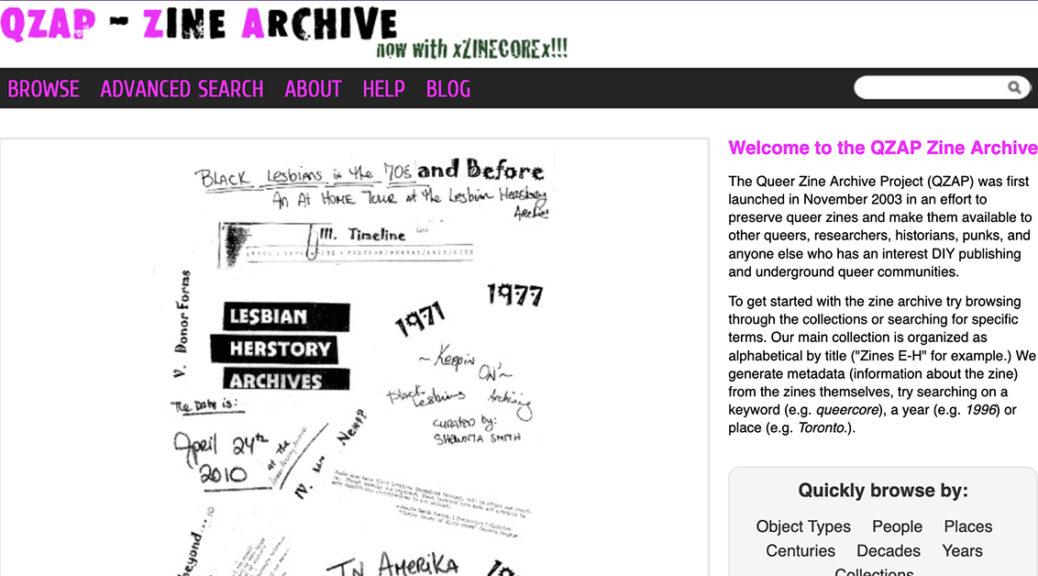
Zines have long been a medium for weirdos, freaks, and outcasts on the margins, which means they’ve been a staple of queer expression. The Queer Zine Archive Project (QZAP) has been digitizing and preserving queer zines for twenty years!
First of all, what are zines? Zines are DIY publications, usually staple-bound and made with printer paper. They’re cheap and easy to produce, and most zine makers give them away for free or sell them at low prices to recoup costs. This allows them to bypass mainstream publishers, so zines are often a medium for marginalized and radical voices.
Zines developed out of Science Fiction fan culture in the 1930s. In the 1970s, the onset of photocopying technology coincided with the rise of punk music. Punk fans (who often overlapped with Sci-fi fans) latched onto zines as a way to write about their favorite bands, share stories, and build community. As such, zines have always been a venue for outsider expression and radical politics. In the 1990s, feminist and queer zine makers really took hold of the medium. Punk communities might have been made up of outcasts, but they weren’t immune to misogyny and homophobia. Women and LGBTQ punks experienced marginalization and discrimination within their scenes, and zines provided a much-needed space to voice these experiences and find other like-minded queers.
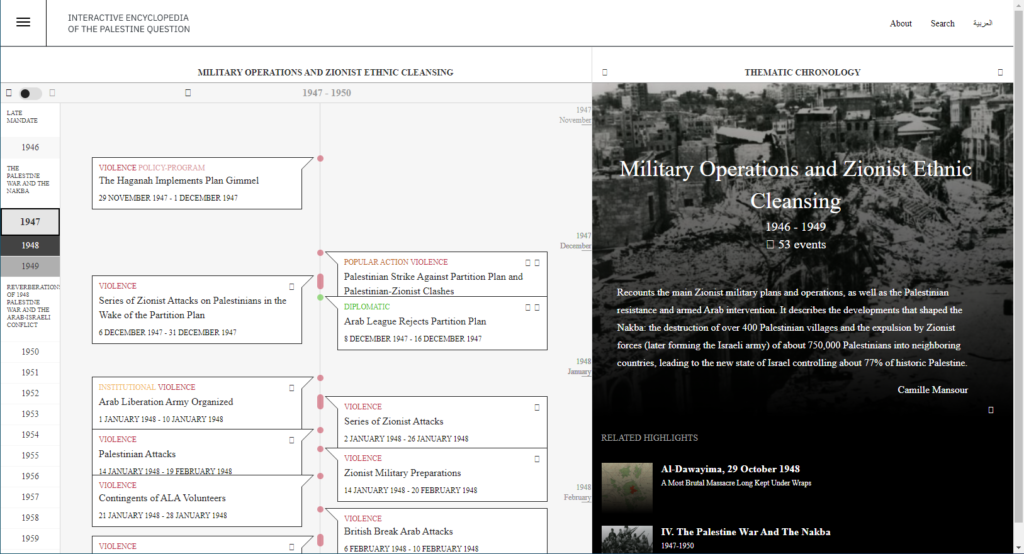
So a project like QZAP is pretty revolutionary! This searchable database is run by a collective based in Milwaukee, Wisconsin, and it is and will remain free and open to use. QZAP’s goal is to create a “living history” so they continue to accept new submissions from contemporary queer zine makers. They hold a broad definition of “queer,” too, recognizing that identities and language change over time. Zine makers submit their physical zines to QZAP, and collective members, usually librarians, archivists, scholars, and graduate students, scan the zines and create the metadata. Like zines themselves, QZAP is a DIY enterprise!
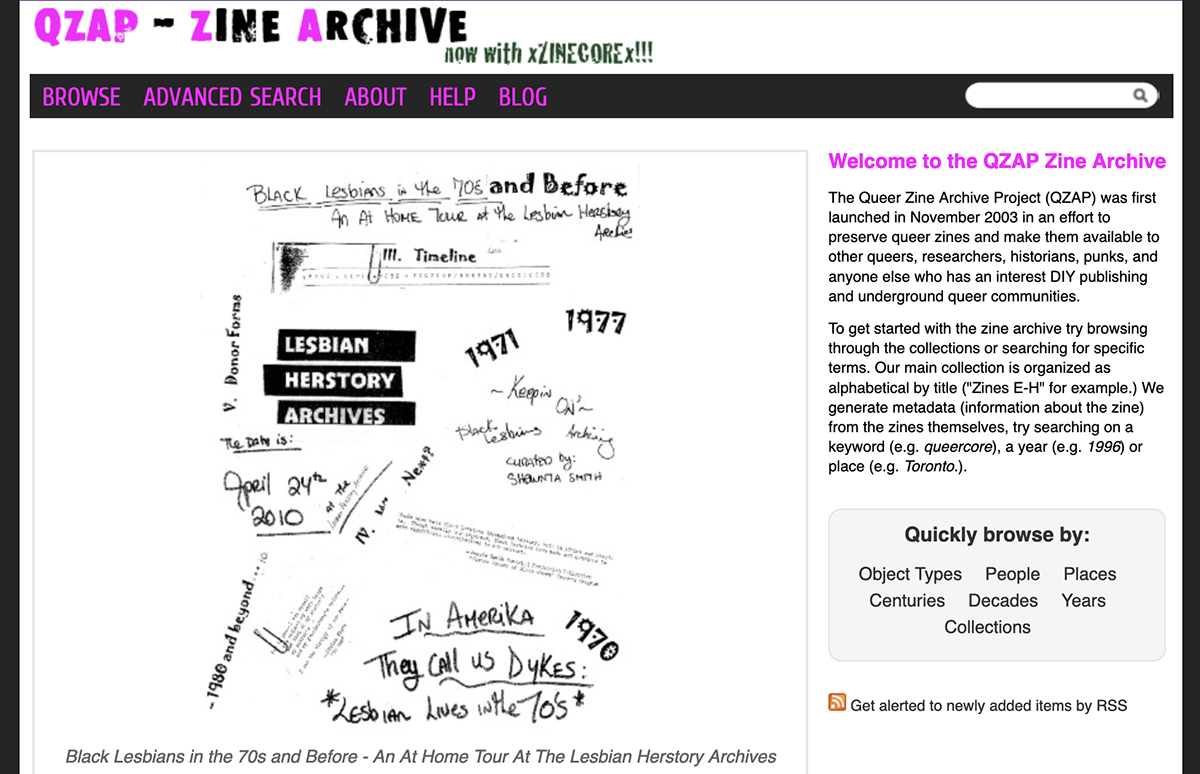
QZAP allows users to browse zines, which is one of my favorite ways to explore their collections. With so much interesting and obscure content, browsing QZAP’s collection is a fun, serendipitous experience. QZAP also has an Advanced Search option for users to find zines by author, place of publication, or year of publication. I’ve used QZAP when working with Women’s & Gender Studies classes so students can see a broad set of queer zines over time. While the website’s look and feel are pretty simple and the technology is a bit dated, students respond enthusiastically to the content. I think QZAP’s simple design and stable technology have made it a sustainable project, especially because it is run by a volunteer collective independent of a university or institution.
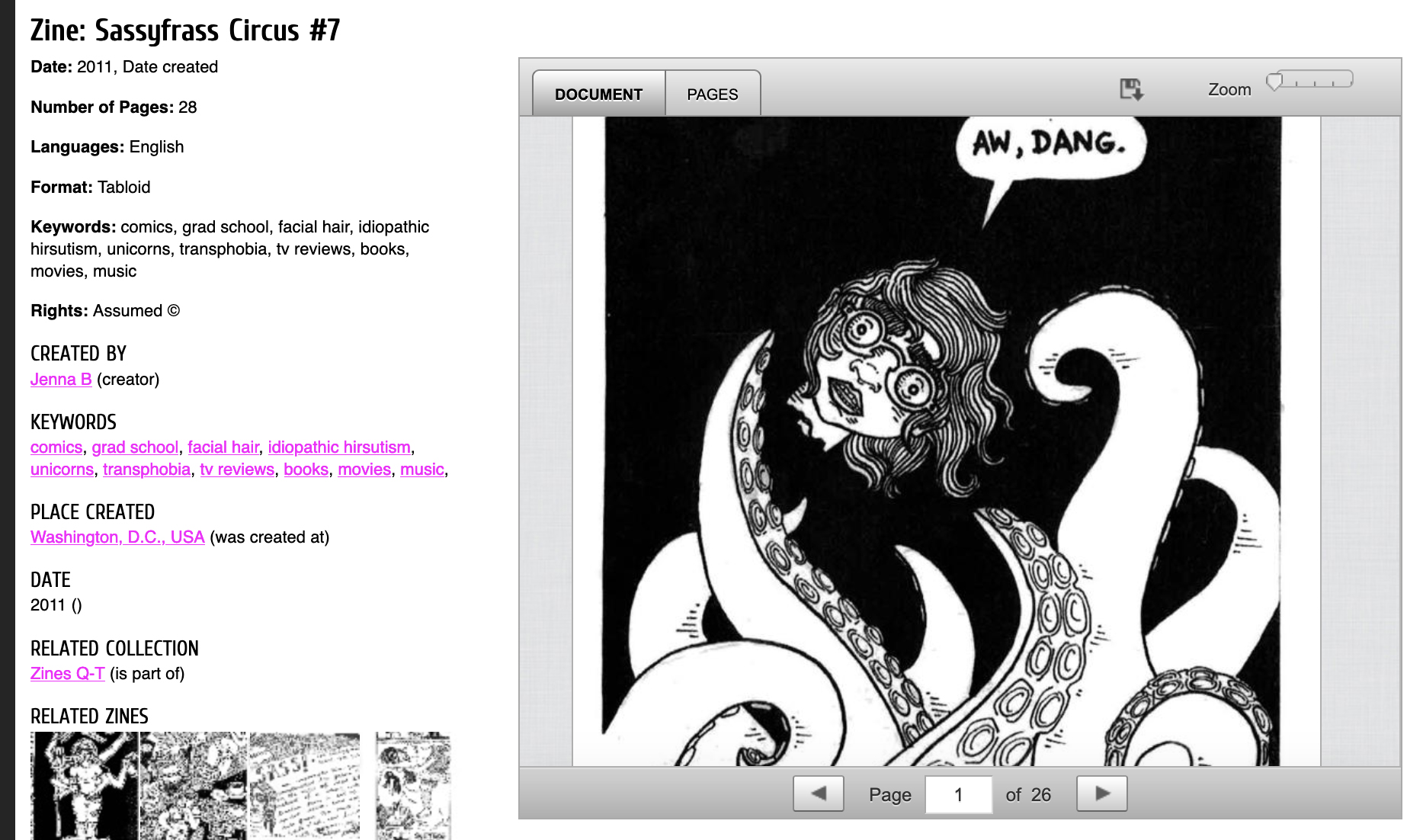
One of my favorite things about QZAP is that it uses a specialized metadata schema just for zines called xZINECOREx, based on the more common DublinCore schema. Cataloging and describing zines are challenging. They often don’t have a title page with publication information. Sometimes no author or creator is listed, or the author goes by a pseudonym. Maybe they have a publication date, but often they do not.

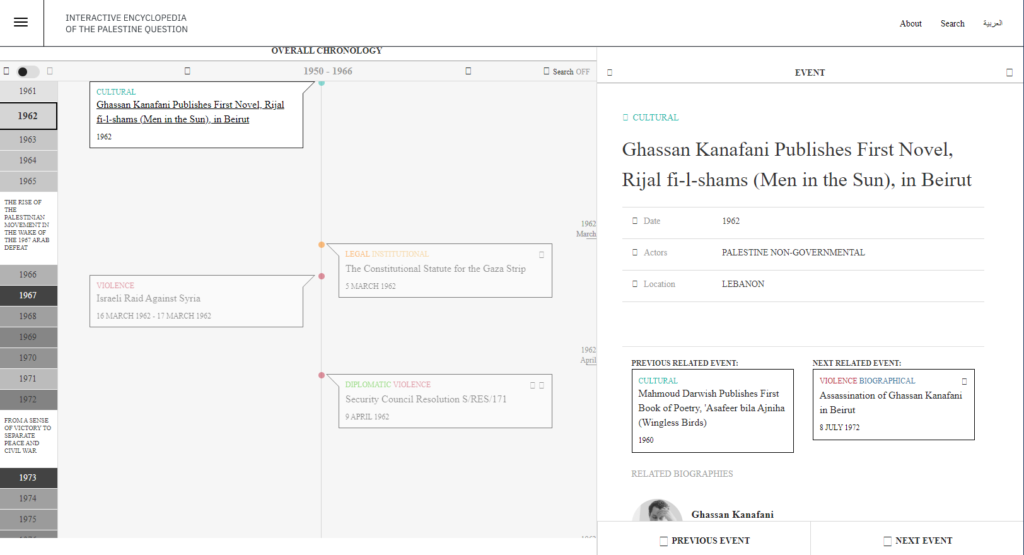
Given these complexities, libraries and archives handle describing zines in all sorts of ways. The xZINECOREx schema provides a standard that can be used across institutions and by independent projects like QZAP. QZAP contributes metadata from its collection to the Zine Union Catalog, which aims to be a single place to search for zines across multiple libraries, archives, and independent collections. Because zines are ephemeral, this catalog is a great resource for scholars interested in the history of zines.
A digital collection like QZAP is vital to preserving the history of these rare, hard-to-find publications, yet there remains great value in studying physical zines. The physical objects provide the reader with a unique, tactile experience. This is especially important for LGBTQ+ history, which is so often erased or hidden. Reading a personal, first-hand account from a queer punk in the 90s – from the actual paper zine that person made by hand – is visceral and powerful. It’s an experience hard to replicate in an online setting. If you find QZAP intriguing, I encourage you to stop by our Zine Collection on the 5th floor of the Fine Arts Library. Our collection has many queer zines, including many published in Texas, and dates back to the 1990s.
Want to learn more about zines? Check out these resources:
- UT Libraries Zines LibGuide
- Zines at the UT Libraries, Digital Exhibit
- From the Punked Out Files of the Queer Zine Archive Project: A Zine of the 2014 Summer QZAP Zinesters-in-residence Program
- Queer As Punk: Queercore and the Production of an Anti-normative Media Subculture by Curran Jacob Nault
- Notes from Underground: Zines and the Politics of Alternative Culture by Stephen Duncombe
- Whatcha Mean, What’s a Zine? The Art of Making Zines and Minicomics by Mark Todd + Esther Pearl Watson