Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the Libraries’ Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
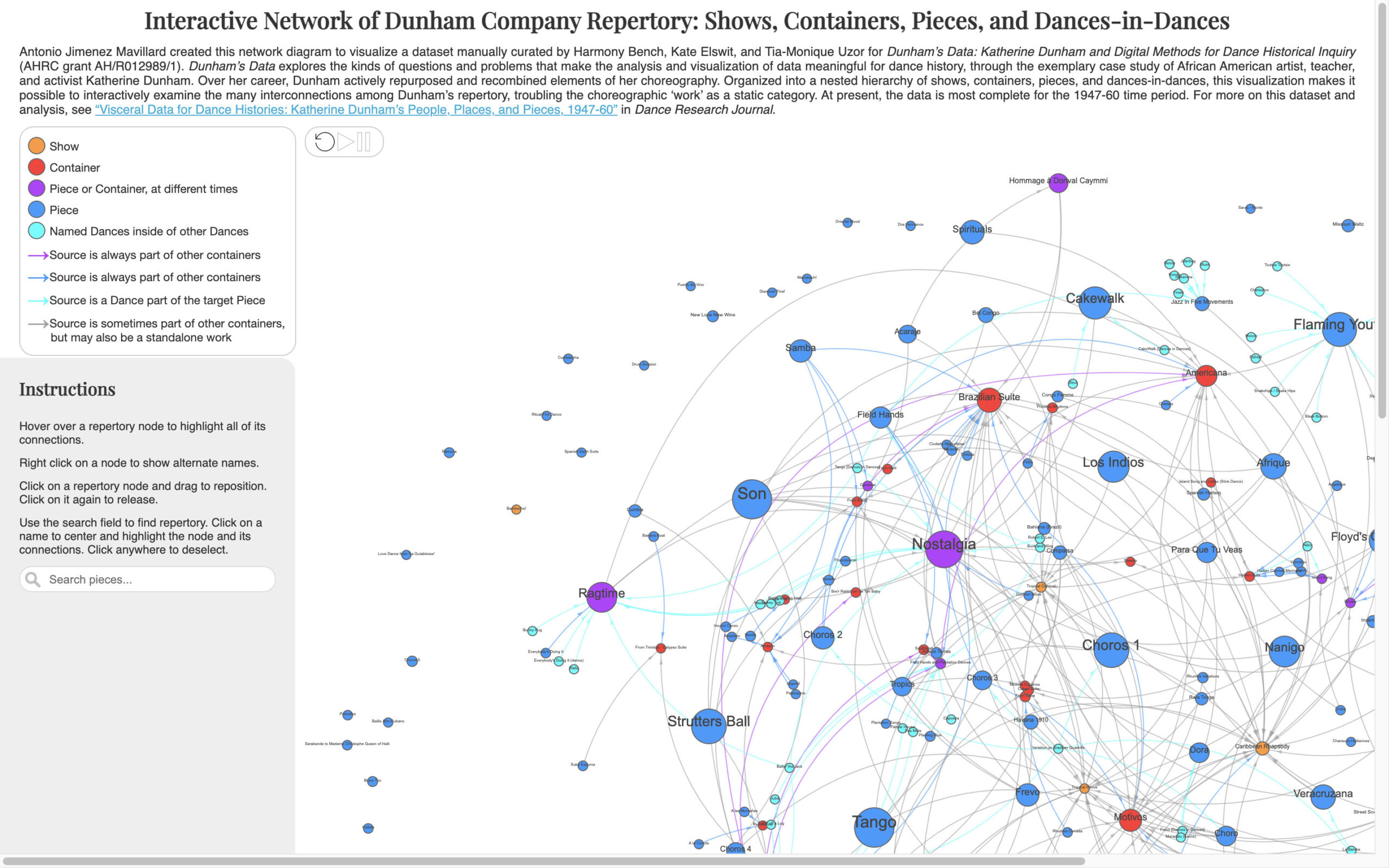
One of my favorite digitization projects is the SF Nexus from Temple University Libraries’ Duckworth Scholars Studio. It’s a digital corpus of 403 Science Fiction (SF) works, mostly novels, anthologies, and single-author short story collections published between 1945 and 1990 in the United States. It was created from scans of physical books in Temple’s Paskow Science Fiction Collection. It’s a notable project because SF has long been sidelined in literary studies, even though research on the genre can bring to light topics well worthy of study – race, gender, politics, futurism, climate change, and technology. This genre bias has carried over to digital humanities (DH), even though computational DH methods can accelerate this research beyond traditional methods like close reading one text at a time.
The project’s first step was to digitize the print books from the Paskow Collection. The team at Temple made the bold decision to physically disassemble the books. Most were cheaply-made paperbacks already in various states of decay and would sustain irreparable damage from digitization. They intentionally chose books that were not already part of the HathiTrust Digital Library, and after the digitization process, HathiTrust ingested these works, preserving them far longer than the physical items might have survived while also making them available to a much wider audience of researchers.
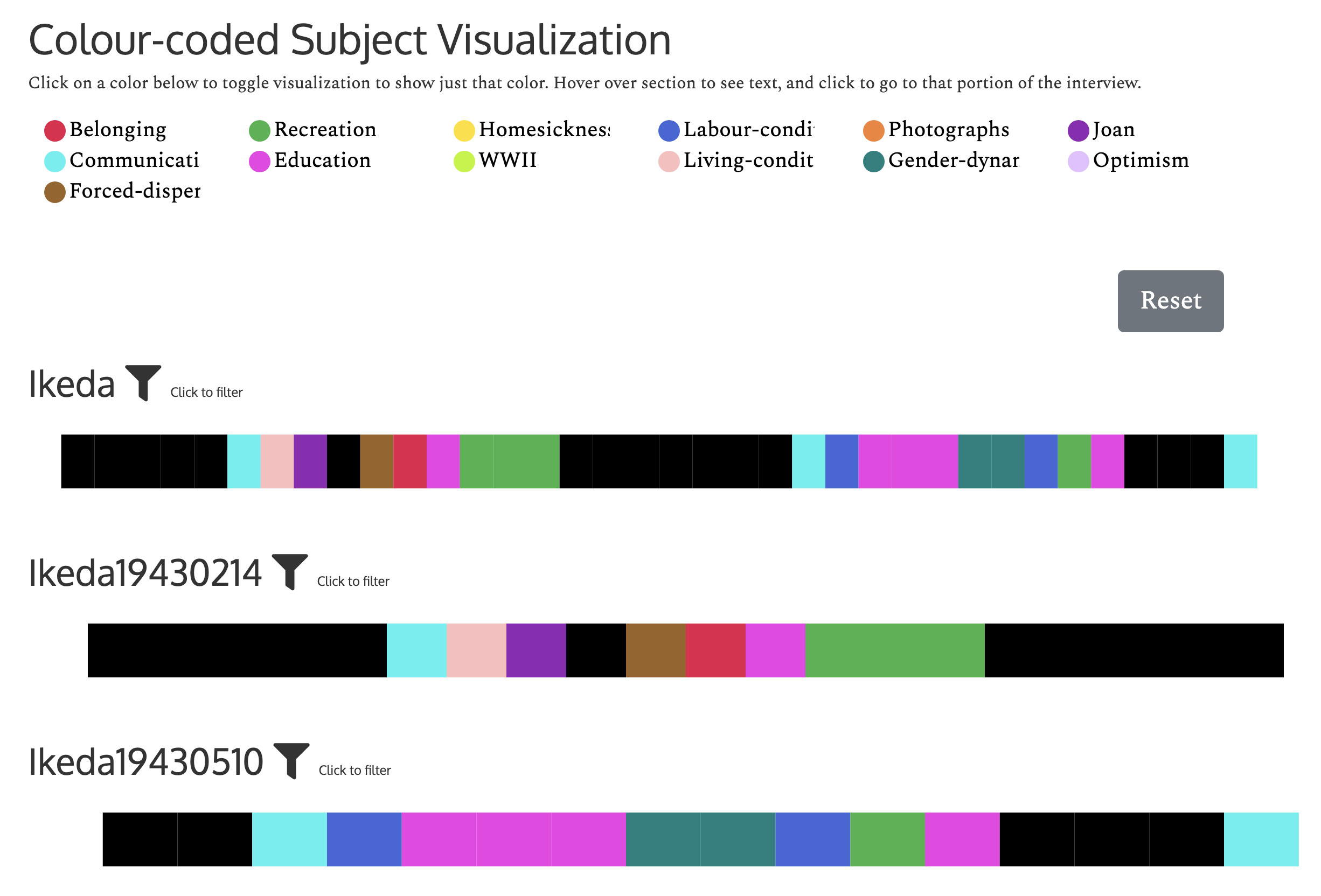
After scanning, the team created the Omeka exhibit Digitizing the New Wave, which highlights mid-twentieth century SF book covers. (Omeka is a commonly-used platform for scholarly online exhibits.) I thoroughly enjoy browsing Digitizing the New Wave, mostly for the entertaining cover art. But it’s also a great work of scholarship in its own right. It sheds light on lesser-known SF novels and writers from the New Wave Era, roughly from 1960-1990. I appreciate how the team structured the exhibit – it’s organized by sub-genre. Visitors can browse early “cli-fi” books (SF discussing climate catastrophe) and find examples of the subversive sub-genre Cyberpunk beyond well-known authors like Philip K. Dick and Neal Stephenson.

A screenshot of the Cyberpunk section from the Digitizing the New Wave Omeka exhibit.
Digitizing the New Wave is a great entry point for anyone interested in DH covering SF (and cover art). But in terms of research potential, the current iteration of the project – the aforementioned SF Nexus – offers a great deal more for computational DH, such as text mining and topic modeling visualizations. To facilitate such projects, the SF Nexus offers several datasets, including one organized by book chapters and discrete sections of books (what they call “chunks”) and CSV files with metadata associated with the corpus, including one of “named entities” (proper names associated with real-world objects, such as place names or author names). These datasets are available through a HuggingFace repository linked from the SF Nexus website.
One aspect of the SF Nexus that I find most interesting is the approach to copyright. All of the works in the corpus were published after 1928, the current cutoff date for materials to enter the public domain, and so are still in copyright. The SF Nexus is pretty small as far as digitized corpora go, with only 403 works. This was an intentional choice, partly due to copyright concerns. Many of the books are orphan works (works in which the rightsholder is difficult or impossible to identify or contact), and the subsequent datasets are designed for non-consumptive use. “Non-consumptive” means the digitized versions of the text are not meant to be read as ebooks, but rather studied at an aggregate level in a quantitative way. Additionally, the website includes a copyright Take Down Notice with contact information for a potential rightsholder to request removal.

A screenshot of the SF Nexus’ Take Down Notice, at the bottom of their Data webpage
Currently, the team at Temple is looking to expand the corpus and find partner institutions with substantial SF print collections to contribute. Temple has also been the home institution for most of the current research generated from the project, so the team is also spreading the word to researchers elsewhere with hopes of seeing more research and publications.
And if all this discussion of digitizing old Science Fiction novels has you curious to actually read some, head over to the PCL! UT Libraries has a collection strength in late twentieth century SF that we continue to build on by collecting new SF novels, short story collections, and anthologies! Learn more about our SF collection on our Science Fiction LibGuide!