As the European Studies Librarian for the UT Austin Libraries, I am interested in exploring and encouraging connections between my subject areas and the broader global community. Understanding and advocating for disability is one way that this sense of global community can be fostered, as disability transcends national boundaries and affects people across the world.
Disabled people have consistently been marginalized and excluded from the historical record. Efforts to remedy this–and to reclaim the history and dignity of disabled people–are ongoing, and are burgeoned by digital studies and practice. Of especial interest at the moment is how the global pandemic has affected disabled people, and how their experience of the pandemic may differ from the non-disabled. The Disability Covid Chronicles from NYU aims to explore the stories of disabled people in NYC and let them tell, in their own words, how they experienced the COVID-19 pandemic.
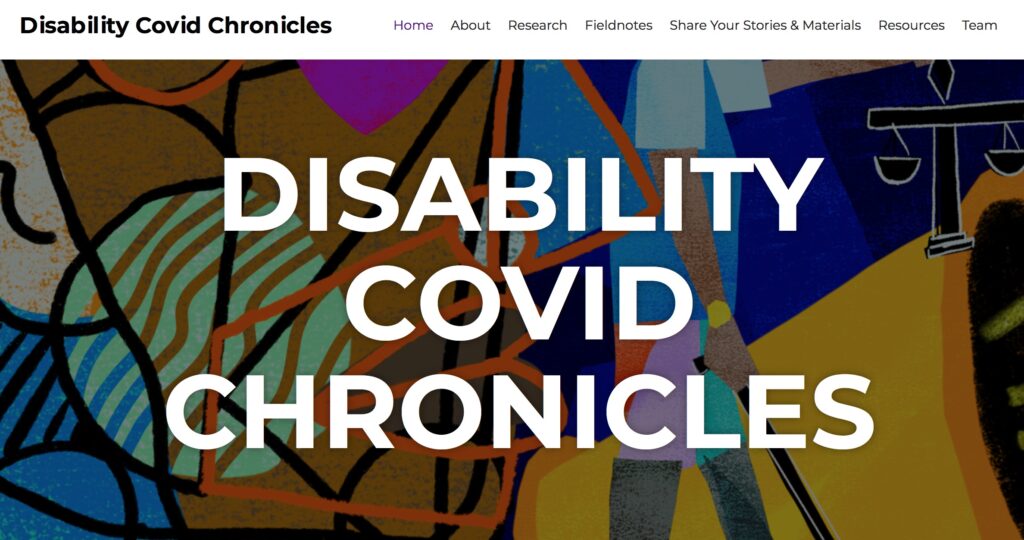
While the project is still ongoing, essays and interviews from research-in-progress are available to view on their website. The project team is preparing an edited volume based on its research during the pandemic, and is also “building a publicly-accessible archive to preserve memories, stories, artworks, and other materials in a range of accessible formats” in collaboration with community members. In the words of the project team members, they “are preserving conversations on social media, records of digital public meetings, and photographs of street art and actions that are otherwise ephemeral. [Their] goal is to chronicle not only vulnerabilities, but creative initiatives for survival under these new conditions that are structured by old inequalities.”

In addition to the essays and interviews linked above, the fieldnotes section of the site highlights notable ephemera and other media–from posters and artwork to social media campaigns and more–that the team has encountered during its research. This is a great way to explore the diverse content available on the site, as the content is reloaded in a random order each time the page is refreshed. Notable entries from the page include this post recapping a survey from Special Support Services, an advocacy group for disabled students and their families, this post preserving artwork by Jen White-Johnson created to amplify the #MyDisabledLifeIsWorthy hashtag, and this post preserving artwork from Roan Boucher/AORTA: Anti-Oppression Resource and Training Alliance. You can also share your own resources at this link.
The site was built using WordPress, a popular content management platform. While free and open-source, WordPress does charge for hosting plans through its website, which can be a barrier for access to some. It also offers a large number of plugins that can make constructing a website less of a burden for those with less technical knowledge—such as the Random Post on Refresh plugin, which allows users to accomplish a similar randomizing functionality to the site’s Fieldnotes section. The site makes use of accessibility features, such as the “alt” tag in HTML, to ensure that those using screen readers or other assistive features can still access the site’s content. WordPress itself also makes a commitment to accessibility in its design and code.
The COVID-19 pandemic has had a particularly strong impact on many disabled people, and having a site that documents and amplifies disabled perspectives and experiences is an important step toward creating a supportive and equitable culture for all. The site serves as a valuable resource related to the global pandemic, and its forthcoming edited volume and digital project will, I hope, further amplify and uplift disabled voices.
Related materials in the UT Libraries collection:
The Disability Studies LibGuide from UT Librarian Gina Bastone: https://guides.lib.utexas.edu/disabilitystudies
Hall, Kim Q. Feminist Disability Studies. Bloomington, IN: Indiana University Press, 2011.