Today, I’ll be highlighting the South Asia Open Archives. The South Asia Open Archives (SAOA) is a rich, curated collection of historical and contemporary resources from and about South Asia. The SAOA collection contains hundreds of thousands of pages of books, journals, newspapers, census data, and magazines with a focus on social and economic history, literature, women and gender, and caste and social structure. The collection includes documents in English and in other languages of the region such as Hindi, Urdu and Bengali.
SAOA is administratively hosted by the Center for Research Libraries, and is the product of a broad consortium of 26 current member research libraries in South Asia and around the world, including the University of Texas Libraries. It is enriched by substantial contributions of content, human and material resources from a community of libraries, research centers, archives and other institutions partnering to bring these resources out for global scholarship and pedagogy.
Some of the titles that have been digitized with direct support from the University of Texas include: Baghi, Viplav, and Viplavi Tract. All three titles have a Leftist/Marxist focus and engage with workers and labor issues.
In keeping with the OA Week theme for this year of Open for Climate Justice, I did a search for climate,in the SAOA Collection, and found over 1200 results ranging from census information, Indian Assembly debates, newspapers, correspondence, and books. SAOA has been digitizing and will be publishing collections of colonial records related to public works (irrigation), forests, land settlement, trade and navigation, and famine that will be available to support the work of environmental historians and climate scientists.
You can find more information about SAOA within the collection in JSTOR, on Twitter, and on Instagram. To suggest sources to add to SAOA or learn more about joining or participating in SAOA, please email them at saoa@crl.edu. UT Austin faculty, staff, and students with questions about SAOA, may also reach out to Mary Rader, South Asian Studies Liaison Librarian. To learn more about open access at UT, please see our Open Access blog or our Open Access LibGuide.
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
This post was written by Jyotsna Vempati, the Global Studies Digital Projects GRA at Perry-Castañeda Library and a current graduate student at the School of Information.
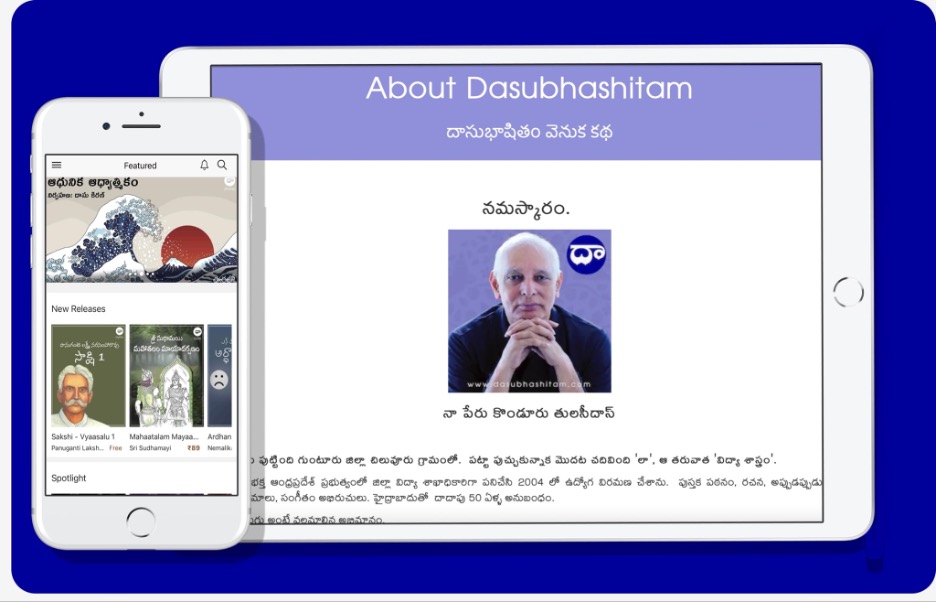
A Telugu (pronounced ˈteləˌɡo͞o) literature classic – Bāriṣṭaru Pārvatīśaṃ, is a novel that I brought along with me despite the strict luggage weight limits of international flights so that I have a piece of my childhood and home with me in a new country. But if I am honest, this was my way of ensuring that I don’t forget how to read and write in my mother tongue. Although the biggest of the Dravidian language family with over 80 million speakers and 4th most spoken language in India, the future of Telugu is in danger from the proliferation of English and other less-regional languages in Telugu speaking regions.
Many believe it is time to take deliberate action to preserve a language that has a rich history and culture, and many compelling literary works that date back to 575 CE. While there is still a sizable reader base for Telugu literature, there is a rising need to make these texts more accessible and visible in today’s digital era. And in comes the first of its kind Telugu audiobook application – Dasubhashitam.
Founded by Konduru Tulasidas and his son Kiran Kumar, this ‘uncommon app’ draws its essence from multiple disciplines that include Literature, Behavioural Science, and Non-Dualism. It promotes personal, professional, and spiritual wellbeing through original content in a style that is simple and straightforward. The app contains free content as well as paid literature works, which can be accessed through subscription plans.I think this app fills the gap by providing an opportunity for those who speak Telugu but face difficulty in reading the script to reconnect with their roots, thus reviving the language from its slumber.
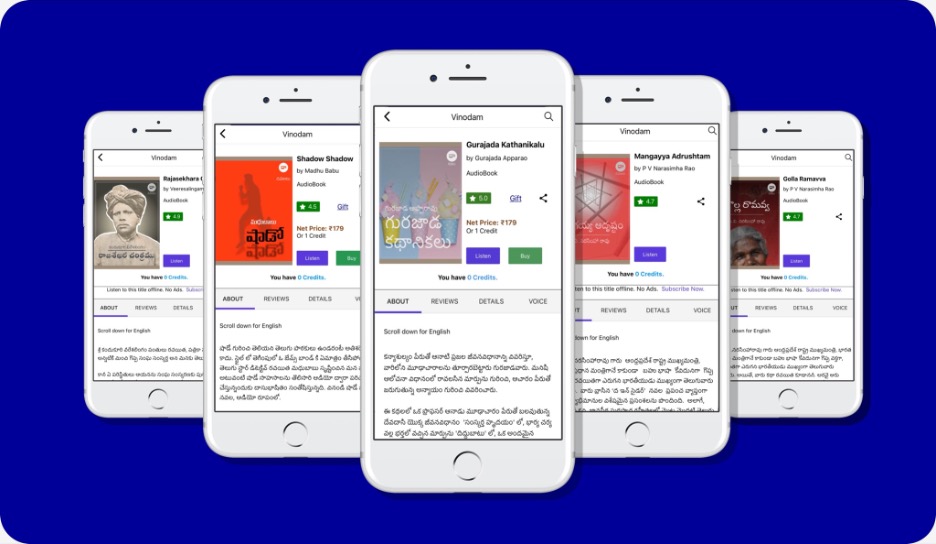
The Dasubhashitam app is paving the way to immortalize the works of both renowned and new authors by creating an ecosystem where people connect Telugu texts to audio content. It contains literary works in various digital formats such as audiobooks, ebooks, podcasts, interviews, and albums within categories like short stories, novels, poetry, wellbeing, and educational content. The audiobooks need a mention of their own due to the deep cultural context within which they’re recorded and presented. Not only is a book read out loud, but some audiobooks of play scripts also have accompanying musical notes that add a touch of the popular Telugu cinema experience, transporting one back to the age of black-and-white films. Another noteworthy aspect of this app is that it offers the opportunity for individuals to suggest a book to digitize, or submit their audiobooks to the app for hosting (after a strict copyright and quality check, of course).
As a student of User Experience Design here at UT, I cannot help but comment on opportunities for improvement when it comes to the user experience and usability aspect of the mobile application. I find that the app’s heuristics are yet to be optimized to make the content more accessible to their user base. Especially, ramping up the in-app search and filter options, standardizing the transliteration of the literary title to the English alphabet (romanization), having uniform navigation gestures across and refining the information architecture would surely minimize user pain points and add value to the overall experience.
This spectacular enterprise is carving out a presence for itself rapidly and, all-in-all, the kind of content and initiatives undertaken by the creators clearly reflects their intentions, namely, to promote the wellbeing of their users. I look forward to witnessing the great potential of this piece of technology, especially as some of the notable names in the world of Telugu literature are available on the Dasubhashitam app.
I’m also delighted to discover that UT Libraries hold a great collection of Telugu literature. One might be encouraged to read one of UT’s print versions of these titles alongside the audio book on Dasubhashitam! See for example the Telugu writings by:
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the UT Libraries Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of, and future creative contributions to, the growing fields of digital scholarship.
I had the lucky opportunity recently to catch Nickoal Eichmann-Kalwara’s presentation on the University of Colorado’s Digital El Diario project at the UC San Diego Digital Initiatives Symposium wherein she advocated for the use of “minimal computing” to achieve “archival justice.” Deeply inspired by her comments but woefully ignorant of the corpus on minimal computing within DS/DH (what seems a combination of activist- and digital-turn on the “less process, more product” concept in archival work), I took it upon myself to learn more as I struggle with the constant nagging tension between achieving the immediate task at hand (“will a simple Google chart effectively communicate my point?”), exploiting technologies to their fullest extent (“boy, I sure bet I would impress folks if I used a sexy Tableau dashboard”), and justifying resources (“this will cost how much??”). When, I wondered, is less actually more in DS/DH, when is more actually more, and how should we negotiate those differences?
Way back in 2017, Roopika Risam and Susan Edwards argued (in “Micro DH: Digital Humanities at the Small Scale”) that the fixation of everything “large” is not conducive to justice across our institutions, our staff, nor our data:
“Digital humanities practices are often understood in terms of significant scale: big data, large data sets, digital humanities centers… This emphasis leads to the perception that projects cannot be completed without substantial access to financial resources, data, and labor… While this can be the case, such presumptions serve as a deterrent to the development of an inclusive digital humanities community with representation across academic hierarchies (student, librarian, faculty), types of institutions (public, private, regional), and geographies (Global North, Global South).”
I found their argument compelling and wondered where I had seen these tensions in practice. As a South Asianist, I had to look no further than the uniquely colonial way of knowing—lexicography–and the uniquely 21st century way of access–digital reformatting.
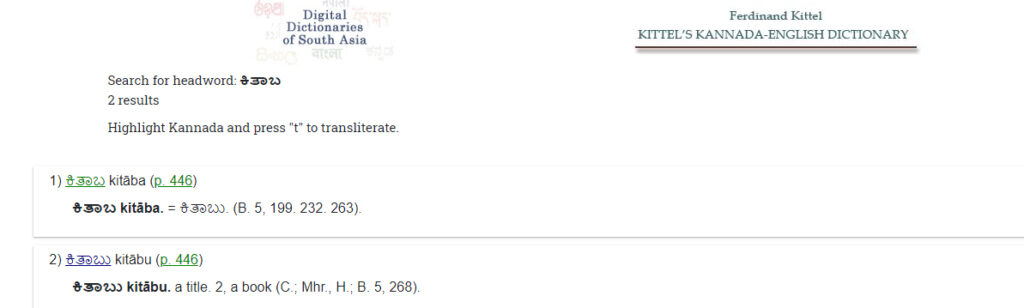
For over 20 years, the Digital Dictionaries of South Asia (part of the Digital South Asia Library at the University of Chicago) has arguably been the gold standard for online South Asian language dictionaries. Recognizing the inadequacies of OCR tools to convert images of most South Asian scripts to accurate text data, the DDSA has utilized strategies such as “double blind keying” to produce highly accurate digital editions of established and respected dictionaries. The process is time-consuming and expensive but produces trusted full-text data that can be used and manipulated in a variety of ways, including those beyond dictionaries. The institutional positioning of the University of Chicago has allowed for many successful grants over the years to fund DDSA, including those from the US Department of Education, the Mellon Foundation, the Association for Research Libraries and others. The DDSA is truly extensive in scope and in impact.
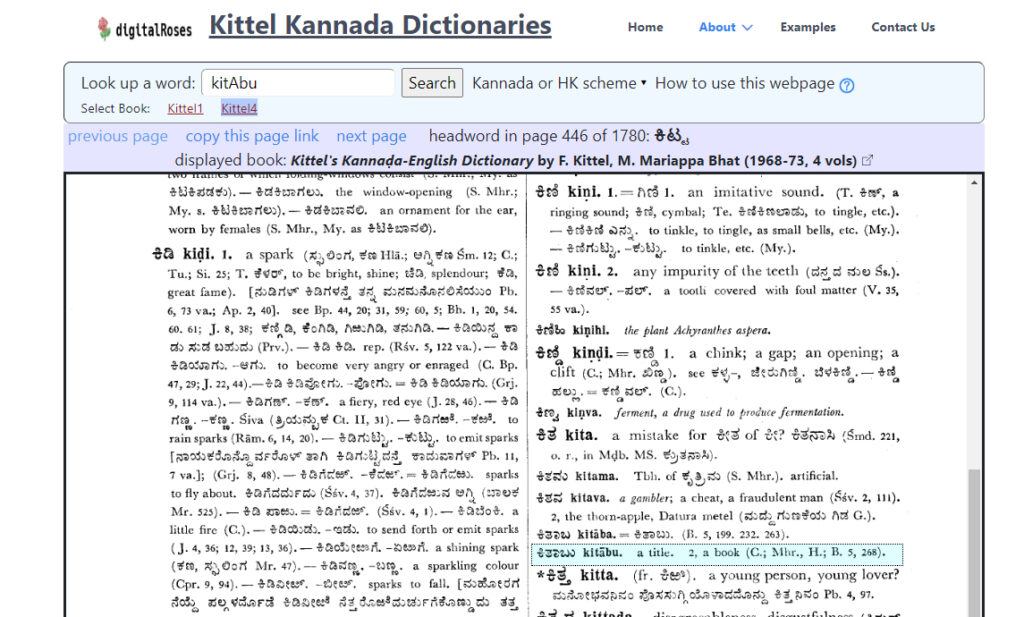
At the other end of the spectrum is the DigitalRoses project. In this pilot, an individual researcher, Gil Ben Herut, Professor of Religious Studies at the University of South Florida, presents another approach to digital dictionary making. Rather than seeking a fully searchable, text-mineable dictionary, Herut suggests that simple encoding that operationalizes headwords alone (rather than the full-text) for navigation within a dictionary is sufficient for most user applications. Using target words, the DigitalRoses approach “resolves a common problem in OCR text ingestion through the utilization of manual indexing of the first entry word on each page in physical media, [thereby… ingesting dictionaries at a fraction of the time and cost of full digitization,… streamlining searching by allowing partial, wildcard and fuzzy searches, and maintaining the richness of the printed layout.”
In comparision, then, we have two approaches to the same problem and therefore two solutions. See, for example, a search for the Kannada word for “book,” Kitaba/ಕಿತಾಬು, in the DDSA version of Kittel’s Kannada-English Dictionary and in the Digital Roses version.
The thoroughly meticulous approaches used in the DDSA model produce a robust and unique digital experience built on fully manipulatable, multiscript data while the simple imaging and only partial inputting of the DigitalRoses project produces a quick digital surrogate to the analog counterpart.
Turning back to “minimal computing,” these two projects offer up models to complicate our understanding of who gets to do what and how in our technologically informed research. Grant funding allows for big data and big research at big institutional levels. Minimal computing allows individuals and less resourced cohorts to also meaningfully contribute to the field. Both approaches have the potential to positively impact users and the creation of new knowledge.
I encourage you to consider where you fall on this debate: is less more? Is more more? And when does it matter?
For more on minimal computing, justice through DS/DH, lexicography, and Kannada, see:
Voluminous lists of banned or redacted books, laced with sanctimonious commentary—or, early modern Spanish “cancel culture.” The illustrated family tree of a womanizing, bald curate named Miguel Hidalgo. Op-eds fawning over every viperous protagonist of the Revolution.
Researchers will find these items and more in the Genaro García Collection. A Zacatecan politico-cum-historian, and eventual director of Mexico’s Museo Nacional de Historia, Arqueología y Etnología, García began amassing books and other items documenting the history, culture, and politics of his country at a young age—a habit he, thankfully, never broke. In 1921, a year after his death, García’s family sold his vast treasure trove of Mexicana to the University of Texas after the Mexican government had reportedly demonstrated little interest. Seven tons of manuscripts, books, periodicals, photographs, and other printed materials made their way to Austin, becoming the seeds of what would flourish into the Nettie Lee Benson Latin American Collection. It is one of the world’s premier archives for the Mexicophile.
Genaro García (center) with museum staff, Museo Nacional de Historia, Arqueología y Etnología, Aug. 15, 1913. Photo: Ramos. Genaro García Collection, Benson Latin American Collection.
Unlike many aspiring young historians, I was never a devotee of archives. I never revered the yellowed, brittle sheets of paper and the “stories” they harbored. Nothing was less appealing to me than spending the better part of a workday in some record office, wearily attempting to distill something relevant from a sea of irrelevancies, surrounded by researchers whose social ineptitude rivaled my own. I had ventured into multiple repositories and each time failed to become a convert. Perhaps this is why I gravitated toward intellectual history when it came time to find my niche. I am a believer in the book and the essay—heresy to the ears of some in the historical profession.
Then I began my position as the Castañeda Graduate Research Assistant at the Benson Latin American Collection. The job entailed creating metadata for digitized selections from the García Collection. I considered it a simple way to add some much-needed lines to my curriculum vitae, not to mention supplement my miserly graduate student salary. Yet it ended up washing away much of the aversion I felt toward archives, and introduced me to another career possibility.
Letter dated Jan. 28, 1536, signed by Juana la Loca (1457–1555), queen of Castilla and later of Aragón. The letter seeks justice after the “confiscation” of Indians (presumably laboring on her behalf) by one Juan Altamirano. Genaro García Collection, Benson Latin American Collection.
After the initial new-job jitters, there was something serenely satisfying about delving into this collection. I was not a visiting researcher working against the clock to find useful bits of evidence for my own studies. I was there to calmly soak it all in, and then produce data, without any personal motive. Moreover, examining these raw materials of Mexican history proved to be a first-rate course in the subject—far more enlightening than any three-month-long seminar could ever be.
Writing metadata is, essentially, an element of the historian’s craft. One has to sit with and scrutinize an item in order to correctly interpret it. Often, this requires a healthy dose of research. Because I was not trained as a historian of colonial Latin America, documents created before the 19th century required additional research to properly contextualize them, as well as a resolute eye to decipher early-modern script. Then there is the authorial question, which occasionally demands another mini investigative journey. The end products are detailed, bilingual descriptions, and other data that, ideally, facilitate the researcher’s job.
Digitization, after all, serves to democratize research and pedagogy by making rare and remote materials easily accessible to anyone with an internet connection.
I began working mostly with documents dating from about 1810 to 1920. The Imprints and Images section of the García archive consists of graphic materials, such as maps, lithographs, and posters. The Broadsides and Circulars portion, on the other hand, is more textual and consists of widely distributed papers relating to Mexico’s War of Independence (1810–1821) and the Revolution (1910–1920), but is no less captivating. These approximately 1,200 items are now viewable on the collections portal, and materials from the photographs, archives and manuscripts, and rare books parts of the collection are continually being uploaded.
Circular de Los Inquisidores Apostólicos Bernardo de Prado y Obejero, Isidoro Sainz de Alfaro y Beaumont, y Manuel de Flores, December 1803. A list of prohibited books from the Inquisition era in New Spain, Guatemala, Nicaragua, and the Philippines. Genaro García Broadsides and Circulars, Benson Latin American Collection.
Currently on my docket are digitized selections from Archives and Manuscripts. This section contains individual historical manuscripts from the 16th to the 19th centuries. Those from the 1500s have proven to be the most challenging, not only due to my lack of paleography skills but also my unfamiliarity with early-modern Spanish grammar. But a fair share of focus and tenacity goes a long way. The “Archives” portion holds the papers of several prominent 19th-century characters, such as Lucas Alamán, the conservative statesman and intellectual, and Antonio López de Santa Anna, the peg-legged vendor of national territory. It will be a welcome break from my travails through the colonial era.
Desastroza Derrota de Francisco Villa – Viva el heroico general Victoriano Huerta, March 1914. Anti-Villa, pro-Huerta propaganda from revolution-era Mexico. Genaro García Broadsides and Circulars, Benson Latin American Collection.
I am glad to play a pivotal role in the Benson’s initiatives to develop its digital collections. Digitization, after all, serves to democratize research and pedagogy by making rare and remote materials easily accessible to anyone with an internet connection. Now, scholars unable to jet off to Austin from, say, Genaro García’s home country of Mexico, can consult his collection from their laptops. Digital content also allows for innovative exhibition practices, like online showcases with interactive features. And perhaps most importantly, digitization safeguards our cultural heritage by producing a virtual “backup.”
Arbol Genealógico del Ilustre don Miguel Hidalgo y Costilla (Genealogical Tree of the Illustrious Don Miguel Hidalgo y Costilla). An extensive family tree of Miguel Hidalgo. Created by Concepción Ochoa de Castro and M. Martínez e Hidalgo, May 16, 1910. Genaro García Imprints and Images, Benson Latin American Collection.
The digitization and metadata creation for the Images and Imprints and Broadsides and Circulars materials were generously funded by the Latin Americanist Research Resources Project (LARRP), Center for Research Libraries, with additional funds provided in honor of Consuelo Castañeda Artaza and her sons. Of course, none of this could have been accomplished without the dedication of several Benson employees. David Bliss, Itza Carbajal, Robert Esparza, Mirko Hanke, Dylan Joy, Ryan Lynch, Madeleine Olson, and Theresa Polk all made indispensable contributions to the digitization and publication of these items.
It has been over two years since I began this position. I am still a devout fan of books and other easily available, published sources. But I am no longer agnostic about the pleasures of archives, at least not the one described here.
Diego A. Godoy is a PhD candidate in Latin American history at The University of Texas at Austin and Castañeda Graduate Research Assistant at the Benson Latin American Collection. Before coming to Texas, he earned an MA in history from Claremont Graduate University. He is broadly interested in the intellectual and cultural history of the region. His particular focus is on the history of criminology, detection, and crime writing. He is author, most recently, of the article “Inside the Agrasánchez Collection of Mexican Cinema,” which appeared in the fall 2020 issue of Portal magazine.
Read, hot & digitized: Librarians and the digital scholarship they love — In this new series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
Over the years of my involvement in Middle Eastern and Islamic Studies (MEIS), I have become something of an advocate for learning modern Turkish. The necessity of facility with Turkish in order to conduct research in MEIS, and more importantly, to carry on scholarly communication in MEIS, grows clearer every year. I would not hesitate to argue that non-Turkish scholars ignore Turkish scholarship at their own peril—it is that central, plentiful, and informative. An excellent example of a scholarly development out of Turkish academe that would be quite useful for MEIS pedagogy and research is İslam Düşünce Atlası, or The Atlas of Islamic Thought. It also happens to be an incredible digital Islamic Studies scholarship initiative.
İslam Düşünce Atlası (İDA) is a project of the İlim Etüdler Derneği (İLEM)/Scientific Studies Association with the support of the Konya Metropolitan Municipality Culture Office. It is coordinated by İbrahim Halil Üçer, with the support of over a hundred researchers, design experts, software developers, and GIS/map experts. The goal of the project is to make the academic study of the history of Islamic thought easily accessible to scholars and laypeople alike through new (digital) techniques and within the logic of network relations. İDA has been conceived as an open-access website with interactive programs for a range of applications. Its developers intend it to contribute a digital perspective to historical writing on Islam: a reading of the history of Islamic thought from a digitally-visualized time-spatial perspective and context.
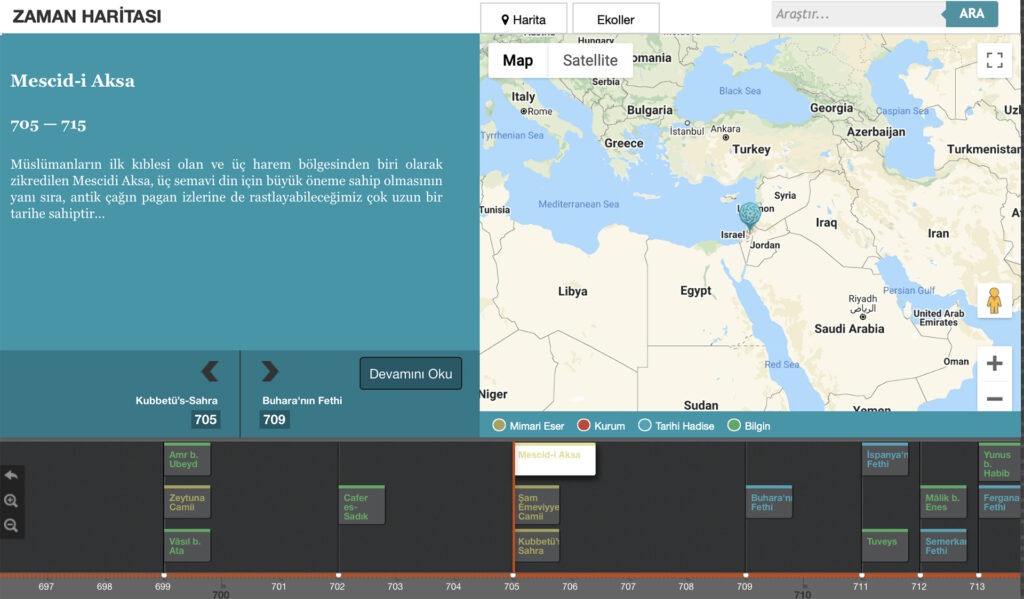
The timeline, noting architectural, historical, intellectual, and institutional events.
İDA features three conceptual maps that aim to visualize complex relationships and to establish a historical backbone for the larger project of the atlas: the Timeline (literally time “map,” which is a more signifying term for the tool, Zaman Haritası), the Books Map (Kitaplar Haritası), and the Person Map (Kişiler Haritası). It also proposes a new understanding of the periodization of Islamic history based on the development of schools of thought (broadly defined) and their geographic spread. İDA endeavors to answer several questions through these tools: by whom, when, where, how, in relation to which school traditions, through what kinds of interactions, and through which textual traditions was Islamic thought produced? Many of these questions can be summed up under the umbrella of prosopography, and in that arena, İDA has a few notable peer projects: the Mamluk Prosopography Project, Prosopographical Database for Indic Texts (PANDiT), and the Jerusalem Prosopography Project (with a focus on the period of Mongol rule), among others.
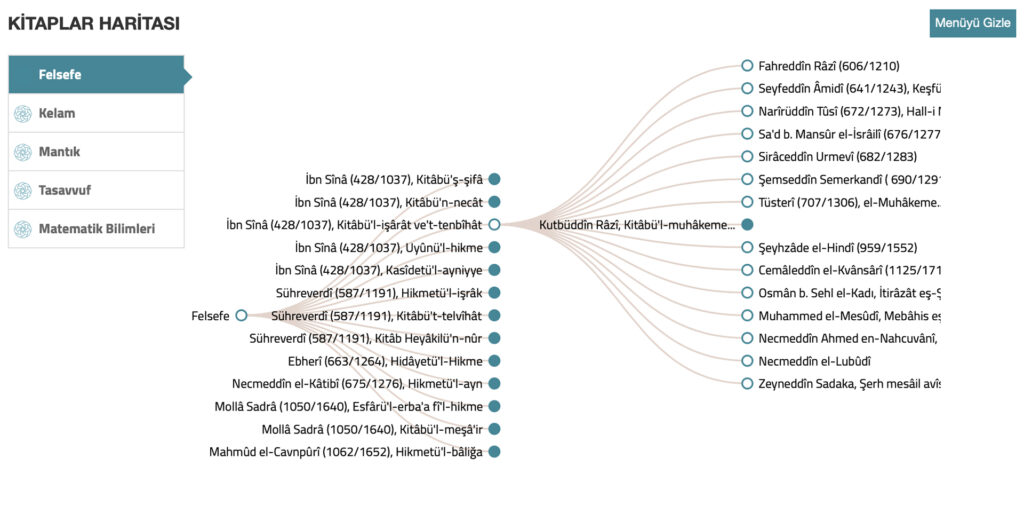
The book map, focusing on felsefe/philosophy and the connections among famous works.
One of my favorite aspects of İDA is the book map and its accompanying introduction. The researchers behind İDA do their audience the great service of explaining the development and establishment of the various genres of writing in the Islamic sciences. Importantly, they also link the development of these genres to the periodization of Islamic history that they propose. The eight stages of genre development that are identified—collation/organization, translation, structured prose, commentary, gloss, annotation, evaluative or dialogic commentary, and excerpts/summaries—share with the larger İDA project their origin in scholarly networking and relationship building. By visualizing the networks of Muslim scholars, as well as the relationships among their scholarly production and the non-linear, multi-faceted time “map” of Islamic thought, İDA weaves together the disparate facets of a complex and oft willfully misunderstood intellectual tradition
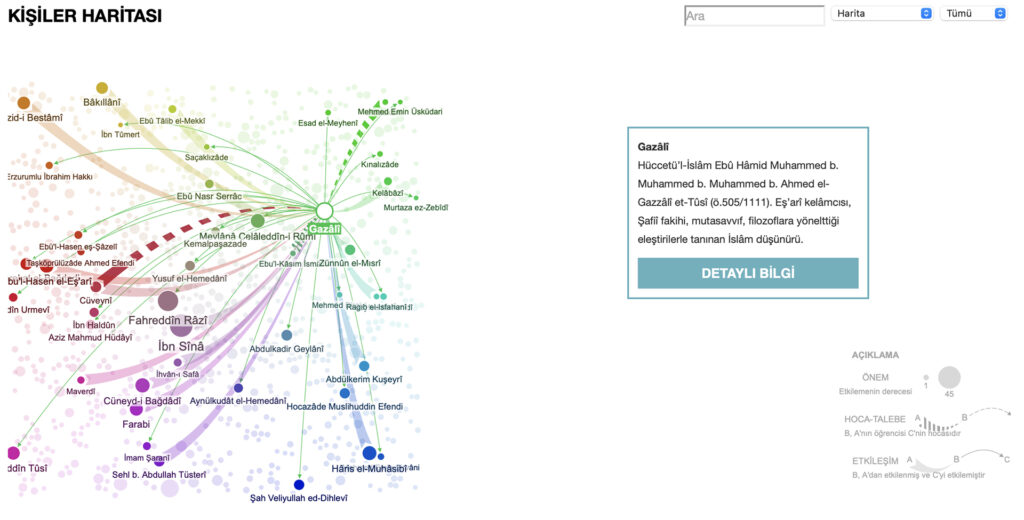
The person map, in this snapshot highlighting the intellectual and pedagogical connections to and from the renowned scholar Abū Ḥāmid al-Ghazālī/Gazâlî.
I encourage readers not only to learn some modern Turkish in order to make full use of İDA (although Google translate will work in a pinch!), but also to explore threads throughout all of the visualizations: for example, trace al-Ghazālī’s scholarly network, and then look at that of his works. What similarities and differences do you notice? Is there a pattern to the links among works and scholars? Readers who are interested in the intellectual history of Islam should check out my Islamic Studies LibGuide, as well as searches in the UT Libraries’ catalog for some of their favorite authors (see here for al-Ghazālī/Ghazzālī, Ibn Sina/Avicenna, and Ibn al-Arabi).
For almost three hundred years, the Spanish monarchs ruled over an expansive empire stretching from the Caribbean to the southernmost tip of South America. World history narratives situate Spain within a centuries-long clash between major powers over territory, resources, and authority in the Americas that ended with the wars of independence. However, these histories tend to devote less attention to the day-to-day processes that sustained imperial rule. My dissertation explores this question through an analysis of the underlying mechanisms that bound the people to their faraway king. A LLILAS Benson Digital Humanities Summer Fellowship helped me to create an online exhibition that demonstrates what the bureaucracy of empire looked like on the ground. (Visit the Spanish version of the exhibition.)
This interactive website serves as an interface with a section of the vast holdings of the Benson Latin American Collection: the Genaro García Collection. Through the exhibition, teachers, students, and community members can explore the events that unfolded when the king ordered a visita—or royal inspection—for New Spain (roughly, modern Mexico) in 1765. The inspection allowed the monarch to keep up to date on local happenings while also identifying areas that could be reorganized. This visita involved approximately seven years of examinations and reforms carried out through a cooperation between the monarch’s appointed visitador—or inspector—and local government workers.
Cover page for this collection of visita documents. G206-01.
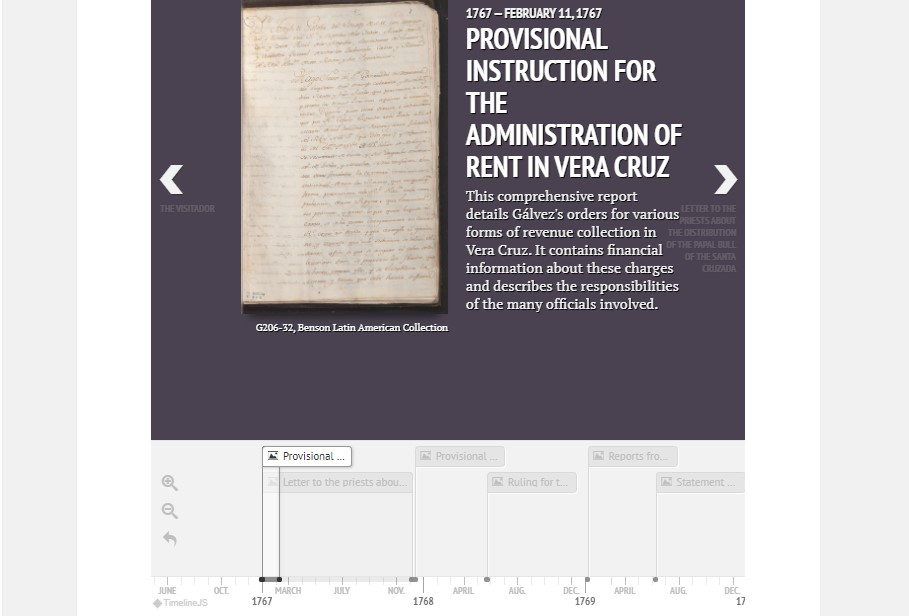
The website offers high-resolution images of the thirty documents from the Genaro García Collection that pertain to this procedure, in addition to brief content descriptions, full transcriptions, information on the individuals involved, and maps of prominent regions mentioned in the sources. All of this information appears in an interactive timeline so that users can experience the process of bureaucracy at work.
The TimelineJS chronology features high-resolution images of the documents included for each date.
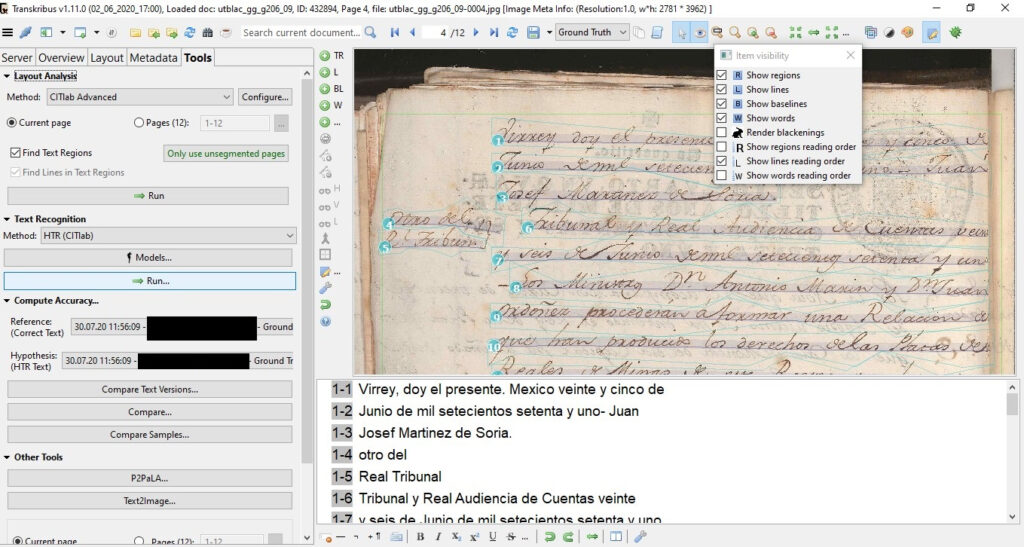
This project benefited from the use of several digital humanities tools, including TimelineJS, FromthePage, and Transkribus. TimelineJS allowed for the creation of an interactive chronology containing the step-by-step process that the visitador followed as he inspected and reorganized the government of New Spain. For users looking to examine the documents beyond the site’s overviews, FromthePage and Transkribus generated full transcriptions of the sources.
This screen shot illustrates the transcription process in Transkribus.
These texts provide opportunities for further exploration, such as data analysis. For example, by feeding the transcriptions into the Voyant Tools website, I was able to generate a word cloud of the most commonly appearing words and phrases in the documents.
Voyant Tools allows for the creation of word clouds, like the one featured above.
The Benson Latin American Collection holds documents covering many regions of the Spanish world across the sixteenth through the twenty-first centuries. During this time, Spain’s hold over its American territories required the constant interaction between royal officials and local populations, and that crossover was often messy. The 1765 visita of New Spain sheds light on the complexities of this process. My hope is that this online exhibition will expand the ways in which people can interact with these sources without having to visit the University of Texas campus in person, and learn from them about the day-to-day experience of imperial management.
Brittany Erwin is a PhD candidate in history. She was a LLILAS Benson Digital Humanities Summer Fellow in 2020.
Read, hot & digitized: Librarians and the digital scholarship they love — In this new series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
A twenty-two-year program that began during World War II and is still relevant nearly sixty years after its conclusion in 1964, the Bracero Program was an agreement between the U.S. and Mexican governments to permit short-term Mexican laborers to work in the United States.
In an effort to stem labor shortages during and after the war years, an estimated 4.6 million workers came to the USA with the promise of thirty cents per hour and “humane treatment.” Of course, we know that loosely defined terms like “humane treatment” present a slippery slope that can erase and omit stories. Fortunately, through the collaborative efforts of the Roy Rosenzweig Center for History and New Media, George Mason University, the Smithsonian National Museum of American History, Brown University, and the University of Texas at El Paso’s Institute of Oral History, many of those once-hidden stories have been preserved and made accessible through the Bracero History Archive (BHA).
The BHA offers a variety of materials, most notably over 700 oral histories recorded in English and Spanish. While the metadata fields for each oral history could be more robust, the ability to hear first-hand accounts and inter-generational stories is a dream come true for primary source-seekers. All audio is available to download in mp3 format for future use.
Apart from oral histories, other resources are also available. Images, such as photographs and postcards, provide visuals of the varied environments that hosted the Braceros as well as portraits of the Braceros themselves.
Again, further detail on these resources would benefit the archive. For example, the photograph above, titled “Two Men,” demonstrates a lack of context needed for a more profound understanding while also acknowledging the potentially constant transient nature of Bracero work. In fact, the very word bracero, derived from the Spanish word for “arm,” is indicative of the commodification and dehumanization of the human body for labor. Workers lived in subpar work camps, received threats of deportation, and lacked proper nourishment, especially given the arduous work conditions.
Additional BHA resources include a “documents” section in which offspring share anecdotes about the Bracero Program and track down information about loved ones. Finally, the site offers resources for middle school and high school teachers to use in their curriculum. Here again is an opportunity to further build out the site for university-level instruction.
Leonard Nadel, “Braceros lean on the wall of a living quarter and attend a camp service in California, 1956,” in Bracero History Archive, Item #2926, http://braceroarchive.org/items/show/2926 (accessed November 12, 2020).
The digital objects in the BHA are worthwhile for those looking to recover an often-overlooked subject in American history that still resonates with themes relating to immigration today. Indeed, farmworkers continue to be exploited and underappreciated despite their contributions to society. This has led to a number of movements, marches, and boycotts in efforts to improve living conditions and wages.
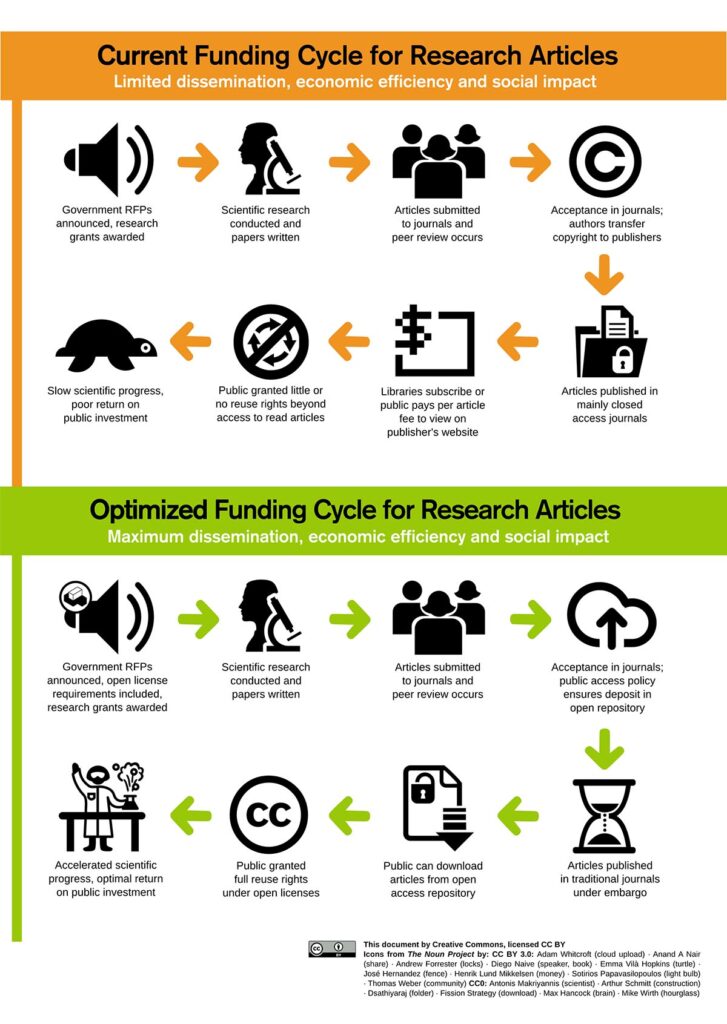
Much of the research being conducted at universities, colleges, and institutes around the world is written up by professors, graduate students, and research associates and published in toll-access (subscription) journals. Anyone lacking a subscription to that journal will not be able to access the articles published there. This creates a serious access problem for many people across the globe.
An alternative method of publishing, called Open Access, allows for anyone to read the results of research for free.
So, why should you care?
The short version:
expensive journals = less access to research results, especially for those outside of wealthy higher-ed institutions
less access = less research being done and/or research not happening quickly because of access barriers
UT Libraries cares deeply about the issue of access for all. For many years we’ve invested in open access publishing and infrastructure in an effort to help shift the scholarly publishing system to a more equitable form.
In celebration of Open Access Week 2020, we’d like to highlight some of the projects we’ve invested in and/or supported over the years. This support can take the form of financial contributions, technical support, content creation, and ongoing promotion and management. We encourage you to check out these open access projects and experience the wide range of disciplines and content types that they represent.
This is a newly-launched open access, peer-reviewed journal in mathematical analysis. One of the founding editors is a UT faculty member and UT Libraries financially supports this journal so that it is free for both readers and for authors.
Consejo Latinoamericano de Ciencias Sociales (CLACSO) is a Latin American open access monograph publishing effort that UT helped organize and financially supports.
SAOA is a collection of open access materials for research and teaching about South Asia. The initial emphasis was on colonial-era materials, but current selection criteria include: value to research, utility for a broad population of users, uniqueness, at risk, and complementary to other resources.
This effort is supported by the Center for Research Libraries and over 25 member libraries, including UT.
“The Information Literacy Toolkit is a collection of resources that faculty and instructors can use to help plan or implement assignments in classes. These resources can help you scaffold research skills into your classes, think of new ways to assign research, and help you assess your students’ work.“
The toolkit was created and is maintained by the Teaching & Learning Services unit within UT Libraries (UTL), although others at UTL are free to contribute.
Content is licensed with a Creative Commons License Attribution Non-Commercial license.
This resource is a starting point for educators wishing to design instructional sessions that incorporate campus collections into final digital projects. Here you will find learning outcomes, things to consider before you begin planning, sample syllabi and assignments, assessment tools, recommended readings, and guidelines for copyright and fair use
This project was created by staff from UT Libraries, LLILAS Benson, and the Harry Ransom Center.
Content is licensed with a Creative Commons License Attribution Non-Commercial license.
The Collections Portal provides free, online access to a sub-set of the UT Libraries vast collections. The platform uses open source technology like Fedora, Blacklight, and IIIF.
The Portal provides access to some of the geospatial data from the UT Libraries collections. It’s also been configured to allow users to search raster and vector datasets from other universities that utilize the GeoBlacklight infrastructure.
All items contributed by UT Libraries are free to reuse.
LADI is a digital repository that provides access to thousands of items from the 1500s to the present. The repository has an emphasis on providing access to collections that document human rights issues and underrepresented communities.
This repository provides open, online access to the products of the University’s research and scholarship. It is hosted by the Texas Digital Library, a consortium of higher ed institutions in Texas that builds capacity for preserving, managing, and providing access to digital collections.
TDR is a platform for publishing and archiving datasets created by faculty, staff, and students at UT. It is hosted by the Texas Digital Library.
Copyright status of items varies, but most are licensed for reuse.
When we started documenting all the things we support, we found the list was longer than is feasible for a single post, so please see our Open Access blog and Twitter account for more examples of open access projects being supported by UT Libraries.
Because we believe that access to information is a fundamental right, UT Libraries will continue to prioritize support for open access publishing, open educational resources, and open data.
We welcome any questions you may have about the OA projects listed above or OA projects you’d like to see us support.
The Nettie Lee Benson Latin American Collection is thrilled to announce the acquisition of the Miguel Ángel Asturias Papers. Asturias, the 1967 Nobel Laureate in Literature from Guatemala, was a precursor to the Latin American Boom. A prolific writer of poetry, short stories, children’s literature, plays, and essays, he is perhaps best known as a novelist, with El Señor Presidente (1946) and Hombres de maíz (1949) garnering the most acclaim. Asturias’s portrayal of Guatemala and the different peoples that live there—their beliefs, their interactions, their frustrations, and their hopes—mark the profundity of his texts.
Miguel Ángel Asturias, photographed in front of his portrait
The Benson is the third repository to house materials pertaining to Asturias’s life work, the other two being the Bibliothèque nationale in Paris and El Archivo General de Centroamérica in Guatemala City. What differentiates this particular collection is the role that Asturias’s son, Miguel Ángel Asturias Amado, played in compiling it over the course of fifty years. Indeed, in many ways the collection is just as much the son’s as it is the father’s. It features years of correspondence between the two, who were separated after the elder was forced to leave Argentina in 1962. This was not the writer’s first time in exile: his stay in Argentina was due to the Guatemalan government, led by Carlos Castillo Armas, stripping his citizenship in 1954. The letters provide insight into Asturias as a father, writer, and eventual diplomat when democratically elected Guatemalan President Julio César Méndez Montenegro restored his citizenship and made him Ambassador to France in 1966. Moreover, scholars will find within these letters a number of short stories for children that would eventually be collected in the book El alhajadito (1962).
Author’s self-portrait
In addition to correspondence with his son, Asturias maintained a longstanding relationship with his mother via letter during his first stay in Paris in the 1920s. Detailed within are the family’s economic hardships as a result of the country-wide crisis in Guatemala caused by the plummeting international coffee market, and information pertaining to the publication of his first collection of short stories, Leyendas de Guatemala (1930). Other communication from this era demonstrates the role that Asturias played in facilitating the publication of other Guatemalan authors and as a journalist for El imparcial.
As a journalist for El Imparcial, Asturias was in constant correspondence about events in Guatemala.
Beyond letters, scholars will find a multifaceted collection. Manuscripts of poetic prose, such as “Tras un ideal” (1917), and an early theater piece titled “Madre” (1918) are included with loose-leaf fragments from El señor presidente. News clippings are also prominent. Those written by Asturias reflect his time at El imparcial while those written about him focus on his Nobel Prize. Perhaps an unexpected highlight is the audiovisual component of the collection. The author contributed an array of caricatures, doodles, and portraits, as well as a robust collection of photographs. Furthermore, there are several audio recordings of Asturias reading his work.
This hand-written manuscript of “Madre” (1918) is Asturias’s first foray into theater.
Finally, scholars will also be able to access studies dedicated to the work of Asturias and first, rare, and special editions of his books. These editions, meticulously collected and cared for by his son, reflect the author’s continued popularity.
La Colección Benson adquiere el archivo del Premio Nobel Miguel Ángel Asturias
Por DANIEL ARBINO
La Colección Latinoamericana Nettie Lee Benson se complace en anunciar la adquisición de los documentos de Miguel Ángel Asturias, Premio Nobel de 1967. El autor guatemalteco fue un precursor del boom latinoamericano. Escritor prolífico de poesía, cuentos, literatura infantil, obras de teatro y ensayos, es quizás mejor conocido como novelista, y El señor presidente (1946) y Hombres de maíz (1949) son las más aclamadas. La representación de Guatemala y sus variados pueblos, creencias, interacciones, frustraciones y esperanzas, marcan la profundidad de sus textos.
El author, frente a un retrato pintado
La Benson es el tercer archivo que reune materiales de la vida de Asturias, después de la Bibliothèque nationale en París y El Archivo General de Centroamérica en la ciudad de Guatemala. Lo que distingue a esta colección en particular es el papel que desempeñó el hijo de Asturias, Miguel Ángel Asturias Amado, en su recopilación a lo largo de cincuenta años. De hecho, la colección es, en muchos sentidos, tanto del hijo como del padre. Presenta años de correspondencia entre los dos, que se separaron después de que el padre tuvo que abandonar la Argentina en 1962. Ésta no fue la primera vez que el escritor se había tenido que ir al exilio: su estadía en la Argentina se debió a que el gobierno guatemalteco, liderado por Carlos Castillo Armas, le había despojado de su ciudadanía en 1954. Las cartas dan una idea de Asturias como padre, escritor y eventual diplomático, después de que Julio César Méndez Montenegro, el presidente de Guatemala democráticamente elegido, restauró su ciudadanía y lo nombró embajador en Francia en 1966. Además, los investigadores encontrarán dentro de estas cartas una serie de cuentos para niños que se recopilarían en el libro El alhajadito (1962).
Auto-retrato por el autor
Aparte de la correspondencia con su hijo, Asturias mantuvo una larga relación epistolar con su madre durante su primera estancia en París en la década de los 1920. Ahí se detallan las dificultades económicas de la familia como resultado de la crisis que atraviesa la sociedad guatemalteca, por la caída del precio del café a nivel internacional, e información relativa a la publicación de su primera colección de cuentos, Leyendas de Guatemala (1930). Otra comunicación de esta época demuestra el papel que desempeñó Asturias al facilitar la publicación de otros autores guatemaltecos y como periodista de El imparcial.
Como periodista para El Imparcial, Asturias mantuvo comunicaciones constantes sobre la situación en Guatemala
Asimismo, los investigadores verán una colección multifacética. Los manuscritos de prosa poética, como “Tras un ideal” (1917) y una obra de teatro titulada “Madre” (1918) se incluyen, tanto como fragmentos de hojas sueltas de El señor presidente. Los recortes de periódicos también son prominentes. Los escritos por Asturias reflejan su tiempo en El imparcial, mientras que los escritos sobre él se centran en su Premio Nobel. Quizás un punto destacado inesperado es el componente audiovisual de la colección. El autor contribuyó con una serie de caricaturas, garabatos y retratos, así como una colección robusta de fotografías. También, hay varias grabaciones de audio de Asturias en las cuales realiza lecturas de sus obras.
Este manuscrito de la obra “Madre” (1918) es la primera incursión de Asturias en el mundo del teatro.
Por último, los académicos también podrán acceder a los estudios dedicados al trabajo de Asturias y a las primeras, raras y especiales ediciones de su trabajo. Estas ediciones, meticulosamente recopiladas y cuidadas por su hijo, reflejan la continua popularidad del autor.
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
Maritime Asia: War and Trade is a multi-media Drupal site which introduces viewers to the complexities of 17th century war and trade in East and Southeast Asia. The open educational resource (OER) is a collaboration among UT History Professor Adam Clulow, Professor Xing Hang at Brandeis University, and the Roy Rosenzweig Center for History and New Media at George Mason University (RRCHNM). This open educational resource can be used effectively for outreach and teaching.
In the historical documents presented and examined on the site, six power contenders are involved: two armed maritime powers, the Zheng family of China & Taiwan and the Dutch East India Company (VOC), two major land agrarian powers, Qing China and Tokugawa Japan, and two continental trade powers, Siam (now Thailand) and Cambodia who took advantages in this global trade and diplomacy competition among major powers. It is interesting to note that the main actors involved were all extensively global.
The website for Maritime Asia: War and Trade has five main themes through which the viewer can explore this multifaceted history:
Maritime Exercise. This part of the website functions as an open educational resource (OER) classroom simulation exercise targeted to 11th and 12th graders and post-secondary students. An instructor’s packet of lesson plans and interesting and inspiring questions for student debate can be downloaded.
Exhibits. Included here are exhibitions of documents that highlight the history of the Zheng family and the Dutch VOC. For example, the first generation of the Zheng family, Zheng Zhilong of southeast China, was globally successful in both piracy and trade from Japan to Siam (now Thailand). As a player in the Ming Dynasty, Zheng Zhilong was appointed “Admiral of the Coastal Seas.” His son, Zheng Chenggong (Koxinga), was born in Japan to a Japanese mother. Koxinga continued his father’s powerful maritime trade and military pursuits after his father’s had surrendered to Qing China in 1644 (and was executed in 1661). Koxinga defeated the Dutch in 1662, forcing out their colonial powers from Taiwan, and he shifted the Zheng family stronghold from China to Taiwan. Another exhibit from the website displays Dutch VOC highlighting their ships and the fort they built in Taiwan.
Timeline. This portion of the website graphically documents major events among the 6 powers throughout the 17th century, from 1600 to 1683.
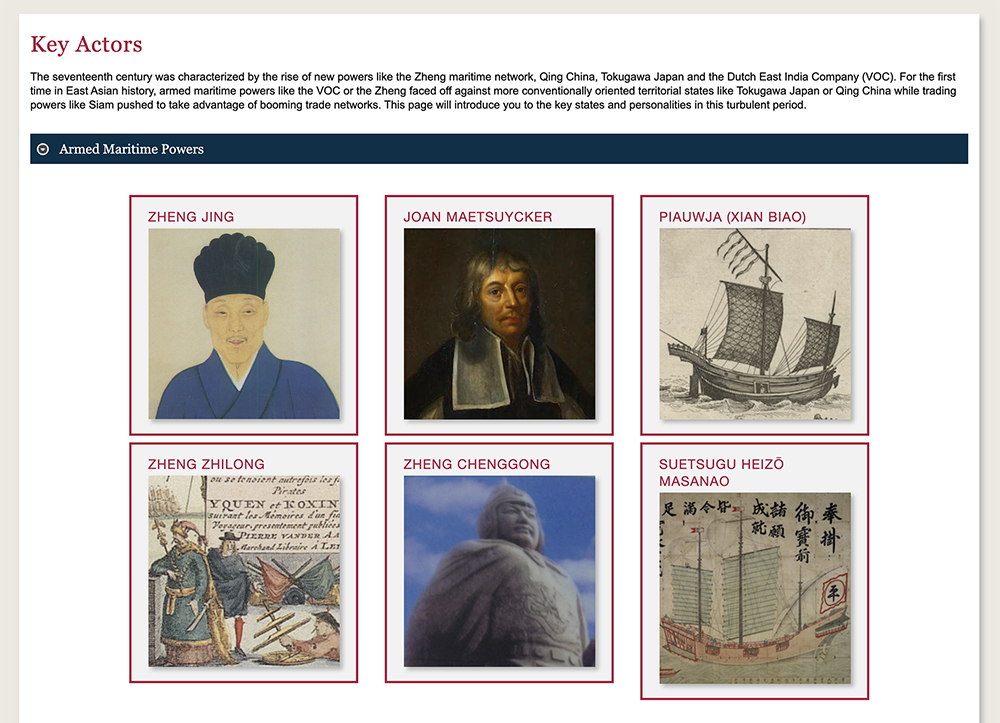
Key actors. Exploring individual personalities is one of the most compelling ways to dive into history. Included here are presentations of individuals such as Zheng Zhilong, the founding patriarch of the Zheng family, Joan Maetsuycker, a governor-general from the VOC, Tokugawa Ietsuna of Japan, Kangxi Emperor of China, King Paramaraja VIII of Cambodia and King Narai of Siam (now Thailand).
Archive. The Maritime Asia website highlights and provides contextualized access to primary source documents. While the physical artefacts are housed in the Nationaal Archief of the Netherlands and the Rijksmuseum in Amsterdam, users can access the digital surrogates through the website.
Further readings on related subjects:
大航海時代與17世紀台灣(Age of exploration and the 17th century Taiwan) 鄭成功來臺 (Zheng Chenggong came to Taiwan) Two open source Chinese learning websites created by the Research Center for Digital Humanities, National Taiwan University.








































{kind=link}