Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
“Baalbek Reborn” is a groundbreaking virtual experience offering free access to users worldwide. Utilizing cutting-edge digital technologies and insights gleaned from decades of archaeological research, the project presents 3D reconstructions showcasing the appearance of Baalbek’s ruins during the 3rd century CE. These reconstructions notably feature prominent structures of the Baalbek temple complex.
Nestled in the Biqā’ valley in Lebanon, northeast of Beirut, Baalbak is an ancient city that flourished as an agricultural and religious center for thousands of years. It is best known for its Roman temple complex, which was called Heliopolis after the Greek for “City of the Sun.” The complex has three temples honoring the Triad of Heliopolis: Jupiter, Bacchus, and Venus, and the city flourished repeatedly under different religious groups’ administration because of its temple architecture. Baalbek remained a significant outpost through Antiquity and the Islamic imperial period, sometimes dramatically changing hands over the course of only months. As Europeans became acquainted with the city in the early modern period, their focus was––and has continued to be––on the remarkable ancient architecture of the temple complex. While the ancient Roman architecture is certainly significant, it is worth remembering that modern archaeologists cleared the Islamic town––which would have featured historic architecture as well––that had been built on the site in order to access the temples. The inclusion of Baalbek as a UNESCO World Heritage Site underscores its significance.
The Baalbek Reborn collaborative project enhances accessibility to the site’s cultural heritage by offering a dynamic virtual exploration of its past and present beauty. Available as a free app for computers, mobile devices, and virtual reality headsets, the “Baalbek Reborn” tour provides interactive, 360-degree views of 38 locations within the city. Users can engage with expert audio commentary in Arabic, English, French, or German, and access additional images and text for detailed information about specific spots. One unique feature is the ability to toggle between the present-day appearance of the buildings and their historical reconstruction from nearly 2,000 years ago. The high resolution of both the photographs and reconstructions allows users to zoom in without losing clarity, while informative text and audio clips provide detailed explanations based on research.
Upon starting the app, users are treated to a five-minute introduction to the site, along with basic instructions on how to navigate the virtual experience. For those seeking a more comprehensive understanding, a detailed tutorial is available for the app’s features. The app offers two main modes of exploration: a guided tour lasting 38 minutes, highlighting the key features of the Baalbek temples, or the option to explore points of interest directly from the map of the temple complex. It is the latter option that some users may find rather disjointed: it is not easy to move seamlessly between points of interest. However, those who wish to explore further are encouraged to view the ruins on Google Streetview for a virtual walk, albeit without the detailed commentary provided in the app.
The collaborative effort behind this endeavor involved three key partners: Flyover Zone Productions, a virtual tour company responsible for the platform’s development; members of the German Archaeological Institute, who contributed content and provided archaeological expertise; and Lebanon’s Ministry of Culture – Directorate General of Antiquities, which oversees the protection, promotion, and excavation activities related to the country’s national heritage sites. Together, these partners have combined their expertise to create a comprehensive and immersive experience that brings the ancient beauty of Baalbek to contemporary audiences.
For further reading in the UT Libraries’ collections, consider the following scholarship:
On a Muslim’s scholars experience of the ruins of Baalbek: Shafir, Nir. 2022. “Nābulusī Explores the Ruins of Baalbek: Antiquarianism in the Ottoman Empire during the Seventeenth Century.” Renaissance Quarterly 75 (1): 136–84. https://doi.org/10.1017/rqx.2021.332.
One of the best parts of serving as the Middle Eastern Studies Librarian for UT Libraries is making and maintaining relationships with scholars, publishers, and vendors. I take advantage of any opportunity to travel to continue fostering these relationships, and my trip to Egypt in late January was no different. I was lucky enough to be able to travel specifically for the Cairo International Book Fair. Over the course of two weeks, I bought amazing books and journals from vendors local to Egypt and coming from around the Middle East, met new suppliers of key research materials, and I was able to connect with dear colleagues new and old.
The Cairo Book Fair is massive. This is not hyperbole: the event is often said to be the largest book fair in the world after Frankfurt, and perhaps more family-friendly than any other. Vendors from all over the world come to offer their wares, and people from all walks of life attend. There are groups of Egyptian schoolchildren on field trips; international students studying at Egyptian universities; scholars of the Middle East from around the world; whole families; teens out for a fun afternoon; and of course, librarians from all over the world who come to find the best, most interesting, rare, or latest publications. I spent my first few days at the Cairo Book Fair at the Children’s Hall and making a preliminary review of the international Islamic vendors in halls 3 and 4. It was in the Children’s Hall that I found the publisher al-Mu’assasah al-‘Arabiyyah al-Hadithah li’l-Tab’ wa’l-Nashr, and they were promoting riwayat al-jib, or pocket novels. In particular, they had produced a boxed set of the full supernatural collection of author Ahmad Khalid Tawfiq. UT Austin already owns a few of his works, including, among others, Mithl Ikarus (Just Like Icarus). The set that I bought includes 81 science fiction, fantasy, and paranormal titles in a small, portable format, with––frankly––delicious cover art. This set, titled Ma Wara’ al-Tab’iah, was the basis of the Netflix series Paranormal.
In Halls 3 and 4, I found the majority of the international and Egyptian Islamic vendors. Of particular interest were the booths and pavilions for the Dar al-Ifta’ organization and Al-Azhar University. The latter had an entire pavilion with exhibits on the manuscripts held at the Al-Azhar Library and the expertise of the preservationists who care for those rare and special materials, as well as art displays and activities for children and adults. I took a peek in their storage room to find what I had originally expected and hoped to find: the classic paperback Azhari texts and textbooks. Researchers focusing on the history of Al-Azhar as an educational institution, or on the history of Islamic education at all levels (for al-Azhar is not just a university, but also operates a K-12 school system), would find these materials central to their work. They are inherently ephemeral, due to their purpose of use and construction, so it was a rare opportunity to find them for UT Libraries’ collection.
Over the following few days, I made my way with more intention through halls 3 and 4 and also explored halls 1 and 2. I had the pleasure of visiting with fellow librarian, Dr. Walid Ghali, who is a professor and director of the library at the Aga Khan University (London). Dr. Ghali recently released three novels of his own, and we had a delightful conversation about librarianship and authorship while at the booth for his novels’ publisher, Dar al-Nasim. I also had the opportunity to speak with Ashraf ‘Uways, the founder of Dar al-Nasim. It was wonderful to learn more about his approach to selecting titles for publication, and especially his interest in supporting the publication of Arabic novels by authors in non-Arabic speaking countries in Africa. With such wonderful publishers at my disposal, I was acquiring quite a bit of incredible material. Each day, I arrived at the fair with a suitcase to fill, and I wasn’t the only one. From students to families to scholars, nearly everyone had a bag or cart of some kind to help them transport home their precious finds.
Traveling to Egypt was also an opportunity to meet with UT Austin’s regular book vendors. I had the pleasure to see George Fawzy, the director of our beloved vendor Leila Books. We were able to check-in in person about the research priorities at UT Austin and how those shape the materials that we acquire through Leila Books, and we were able to catch up on the state of libraries in North America and publishing in the Middle East. Visiting the Leila Books office is a delight for me because I get to see their incredible work in action, meeting the folks behind acquiring and shipping our materials. I always have to get a photo with the latest UT Austin shipment, and sure enough we had several boxes that were about to be sent out.
Additionally, I was able to meet with a new vendor who specializes in rare materials and visit his warehouse on the outskirts of Cairo. It is from this vendor that I have been able to acquire unique periodicals, including al-Majmu’ah al-Da’imah and al-Majallah al-Misriyyah li’l-‘Ulum al-Siyasiyyah (the Egyptian Journal of Social Science), which I brought back from this trip. Al-Majmu’ah al-Da’imah is a huge, multi-volume work that compiles the official record of judicial decisions issued in Egypt since the beginning of the national court system in 1883, and I would not have been able to locate it without this vendor’s help and some luck. I also found out-of-print significant, even rare, materials from the book market of Azbakiyyah in central Cairo. With the Cairo Book Fair on, the entirety of Azbakiyyah market moves to the Fair, where they have their own dedicated section. The Azbakiyyah booths are the most popular and most lively of the Fair, with materials moving in and out constantly. If you ever want to find a particular scholarly edition, or affordable novels, Azbakiyyah, or perhaps its section at the fair!, is the place to go.
My trip to Egypt was not only about acquiring pivotal materials for the UT libraries—I also took the time to visit key Egyptian cultural heritage institutions and to meet with scholars. I had the honor of finally meeting Dr. Nesrine Badawi (the American University in Cairo) in person. We had an engaging conversation about current trends in Egyptian scholarship and discussed her most recent research on Islamic law and the regulation of armed conflict. Additionally, I was able to visit Alexandria, the second largest city in Egypt, and spend a day at the Bibliotheca Alexandrina. Although I have visited this beautiful library and its extraordinary collections before, it is always worth a trip for the new exhibits and rotation of special collections on display. On this visit, I was able to tour the reconstructed private library of renowned journalist and director of al-Ahram newspaper, Mohamed Hassanein Heikal. The extensive exhibit was a stunning look inside Heikal’s education, career, and personal and professional relationships. For my own intellectual amusement, I spent a great deal of time in the rare books room, reviewing the latest rotation of centuries-old manuscripts. Bibliotheca Alexandrina now boasts a significant collection of ancient Egyptian art and contemporary Egyptian art, ranging from paintings to sculpture to ceramics.
It was a delight and an honor to be able to return to Egypt and to visit the Cairo Book Fair this year. I am sincerely grateful to the Center for Middle Eastern Studies, the UT Libraries, and our generous HornRaiser donors for making this trip possible. I look forward to my next trip and the caretakers and creators with whom I will forge relationships.
Throughout fall semester 2023, a cohort of UT Austin graduate students worked overtime to examine the ethics of digitization and create frameworks for approaching their research in a digitizable environment. They took on the “The Theory & Practice of Digitization Community Symposium” program (co-sponsored by the UT Libraries and the Andrew W. Mellon Fellowship for Diversity, Inclusion & Cultural Heritage at the Rare Book School) in addition to their regular coursework and thesis/dissertation research and writing commitments. This program aimed to expand the graduate students’ researcher skill-sets and build reflective approaches to their future professions. The cohort’s efforts culminated in a community symposium that was held on November 9, 2023, in the PCL Scholars Lab, where students, faculty, staff, researchers, and Austin community members came together to learn more about the digitization of cultural heritage.
Each of the students presented on their research, experience in the program, and reflections on digitization of cultural heritage. We have collected their insights to share with you here in the hope that their observations will enlighten the work of others, too.
Saghar Bozorgi (PhD student, Department of Middle Eastern Studies)
I started the Theory & Practice of Digitization program thinking about ethical considerations when in/using archives, but mainly looking to get myself familiar with digital methods and whether they can help my project. By the end of the workshop, I learnt how emphasizing a researchers’ project over the archives can reproduce power relationships and hierarchies between different communities and people, especially between the researchers usually located in the “Global North” and the archives that are assumed to be “waiting” for digitization in the “Global South.” As a result, I am now thinking about going beyond my own project and broadening my horizons and considerations when approaching an archive.
In my letter of interest to attend the workshop I wrote about my near-frustration with “the laborious nature” of data collection and its initial analysis, which for my project translates to an infinite period of data collection, leaving little time for writing. This problem “brought me to the idea of digitization and processing texts using digital methods to speed up the process and broaden opportunities for what can be done.” Using digital methods proved to be way more complicated for a Windows user working with primary sources in Farsi. I learnt that OCR programs work with images rather than pdf, so I changed my approach to using Google Docs, which I had tried before in unsuccessful attempts.
While digitizing parts of Ittila’at Mahiyaneh, I was able to recognize some aspects of archival processes and a tiny bit of “what gets to be archived” or “heard” in my own thought process and decision-making. When selecting samples to show during my presentation, I was conscious about the reason why each piece is important. I was hoping to give voice and power to the material that is less visible or invisible in today’s academic and public discourses. One of the pages that I wanted to show was a page in a 1948 issue dedicated to “Palestine” which was continued in several issues. Nevertheless, I persuaded myself to go with other material in order to protect myself and those around me from possible “trouble” and funding cuts, especially because of a recent scary border-crossing experience and the fact that I was not sure about the costs and benefits in a room with a relatively small (and probably sympathetic to Palestinian cause) audience. I remember a point raised in the very first session of the workshop regarding how the archival process has to be considerate of the communities it is serving today so as to not hurt them by using hurtful descriptions. Thus, I have learnt that digitization is not just about scanning material and making them available, but it is also about how archival material, now empowered with a digitized medium, can be talked about. The contrast between my own self-censorship to show the name of Palestine and the keynote speaker’s powerful discussion of the silencing of archives in Israel makes me wonder not only about “what gets digitized and how it gets digitized,” but also who can digitize.
Marcus Golding (PhD student, Department of History)
The Community Symposium on the Theory and Practice of Digitization has provided a valuable hands-on experience for graduate students in digitizing historical records while fostering critical reflection on these processes. Throughout the four sessions, we learned about the best practices in handling cultural heritage materials and digital tools to explore the materiality of these objects. Our interactions with archivists, librarians, and scholars also delved into the politics behind digitization, power imbalances, access to sources, and the significance of community involvement in such initiatives.
For me, the Symposium offered a chance to delve deeper into the issue of privacy within archival collections. Specifically, the complexities arising from balancing open access to materials from historically marginalized groups with the issues of consent regarding the publication of historical documents originating from these communities. Often, the resolution to this issue is complex. The potential to restore the voices of minority groups can sometimes clash with a community’s desire to shield certain aspects of its history from external viewers. Additionally, the Symposium broadened my understanding of digitization best practices and digital tools. I found the insights into setting up camera stands particularly relevant due to the ongoing digitization projects undertaken by my non-profit organization, the Venezuela History Network, in Venezuela.
During the Symposium, I worked with two annual reports (1973) from a Venezuelan oil company, Mito Juan Company, and an American firm, The Creole Petroleum Corporation, both of which operated in Venezuela during the twentieth century. I applied OCR to these texts to facilitate textual analysis, identifying silences and points of convergence between these enterprises in the context of the impending state-takeover of the national industry scheduled for 1976. Through this hands-on experience with digitization equipment, digital tool literacy, and critical reflection on historical documents, the Symposium underscored principles that I firmly uphold. These principles revolve around democratizing access to historical knowledge and community engagement in digitization projects. The end result is to help build collections that safeguard the cultural identity and historical memory of various groups or institutions for posterity.
These are the same guiding principles driving our initiatives with the Venezuela History Network. Our organization is currently involved in at least six ongoing or upcoming projects in collaboration with public institutions, private individuals, and NGOs. The Community Symposium on the Theory and Practice of Digitization has highlighted the importance, as well as the nuances, of making historical knowledge openly accessible. This experience will continue to shape my dedication to the preservation of cultural heritage in the years ahead.
Junika Hawker-Thompson (PhD student, Department of African and African Diaspora Studies)
This archival manuscript is from an 1822 court trial titled “Trail of a Slave in Berbice for the Crime of Obeah and Murder” from the Black Diaspora Archive here at the University of Texas at Austin. Broadly, my dissertation project explores how colonial violence shapes race and gender relations within the Demerara region—which is another river region not too far from the Berbice region where this incident takes place. So, when I came across this document, I was interested in thinking through how this colonial document––which is well preserved, clear in its text (meaning, it was instantly machine readable post-digitization), and was bound tightly before my digitization process––plays a role in how law, criminality, and blackness interact within colonial British Guyana.
This case is invested in convicting an indigenous, or Black man, Williem, of murder and “obeah.” The court documents oscillate between calling Willem, “negro” or “native.” For further context, obeah is understood as an African root working, herbal, and spell-casting practice that can impact physical illnesses and metaphysical situations that may require assistance. This practice can be traced back to maroon societies and enslaved people enacting care of each other, themselves, and their larger communities. Obeah can be understood as a practice of agency, liberation, resistance, or care. When considering this brief history, what does it mean for “obeah” to be in a relationship with murder—the worst offense based on Christian morals and law?
I focus on this document because I am interested in how the colonial gaze of this case constructed law and criminality in colonial British Guyana and post-colonial Guyana. I am also interested in what isn’t documented–the dance that allegedly led to the murder of another enslaved woman, the embodied routine of this obeah practice, and obeah being synonymous with murder. While I am not attempting to suggest that murder is correct or should be overlooked, I am more interested in this process of equating a spiritual practice established in maroon societies to murder. I am interested in a practice of witnessing—beyond the colonial gaze—that might highlight the depth of this practice and the presence of ritual.
The future implication of this project is a continued witnessing to honor the complexities of spiritual practice and criminality under colonial regimes. I also wonder about the limits of digitization. Is it possible to make clear this witnessing of ritual and practice in this technological space? I plan to continue to work with this document with the hope and goal that this manuscript will assist in understanding the intimacies of race and gender formation in Guyana.
Raymond Hyser (PhD student, Department of History)
Pierre Joseph Laborie, a French coffee planter in colonial Haiti, fled the island during the throes of the Haitian Revolution and took up residence in nearby British Jamaica. As a thank you, Laborie used his expertise and experience as a coffee planter to write a book to benefit Jamaica’s British coffee planters. Published in 1798, Laborie’s The Coffee Planter of Saint Domingo provides an intimate look at the cultivation and manufacture of coffee in colonial Haiti prior to 1789. Although Laborie’s target audience was the British coffee planters of Jamaica, his work quickly went global. It found its way to Brazil, where its Portuguese translation significantly influenced Brazil’s coffee culture. Laborie’s book also reached Cuba, where a publisher there translated it into Spanish. As the nineteenth century progressed, Laborie’s book spread as far as the British colonies of Ceylon and India. Laborie had written the equivalent of an eighteenth-century New York Times Best Seller.
Because of its fame and widespread distribution, Laborie’s book is readily accessible online and at many libraries. A quick WorldCat search reveals dozens of libraries across the world have physical copies, and most of the editions are fully digitized. However, the 1845 edition, printed in Ceylon, does not share the accessibility of the other editions. There is no digitized version, and I have only been able to find two physical copies. One of them is, coincidentally, at the Perry-Castañeda Library. Boasting torn pages, damaged bindings, and held together with several pieces of Scotch tape, UT’s edition looked every bit like a 175-year-old book that had, quite literally, traveled around the world. After I first discovered the book in the fall of 2019, my form of preservation work was keeping it locked away in my desk drawer, where even I rarely consulted its contents. It was not until the Theory & Practice of Digitization Community Symposium that I gained the knowledge, and the courage, to take concrete steps for the book’s preservation through digitization.
Along with being exceedingly rare, this particular edition perfectly lends itself to digitization because it provides a fascinating window into a globalized network of knowledge circulation from the late eighteenth to the late nineteenth century. The number of editions and their geographical spread allow for a comparative study to trace how Laborie’s work changed, or did not, over time and in different geographical contexts. Using OCR (optical character recognition) and text mining methods on the newly digitized 1845 edition, I uncover the genealogy of knowledge contained within Laborie’s work. I highlight how little that knowledge changed in the approximately 50 years that separated the original from the Ceylon edition. Besides a new three-page preface, three short appendices, and different formatting, the Ceylon edition is identical to the original. Even Laborie’s footnotes from his 1798 edition persist within the 1848 edition. The digitization of the Ceylon edition of The Coffee Planter of Saint Domingo increases the accessibility for an otherwise nearly inaccessible work. It also provides a means for scholars to apply digital methods to uncover a global network of knowledge development and dissemination.
Mercedes Morris (Dual master’s degree student, iSchool & Center for Middle Eastern Studies)
I am a student in Middle Eastern Studies and Information Sciences, with a focus on paper preservation. During this symposium program, I worked on digitizing al-Waraq wa al-Waraqun fi al-Asr al-Abbasi, a book on paper in the Abbasid Era. The Abbasid Era is an important era in Middle Eastern history for the rapid increase in written works due to the new technology of paper. There are many myths attested to explain the transfer of papermaking technology from China to Iraq, but these are not verified, and papermakers of the Abbasid Era quickly made this technology their own and quickly built on it, with improvements from these papermakers making their way back to China.
While digitizing this book and reading through it about the history of paper and papermakers in the Abbasid Era, the parallels between the new technology of the Abbasid Era–paper, in this case—and the digitization technology of the present day became clear to me. Paper, like digitization, allowed for increased access and production. Paper, even as a new technology, was cheaper and less labor-intensive to produce than papyrus and parchment, allowing more works to be produced and disseminated. Digitization also allows for greater access for people around the world to physical, written materials today, including rare documents and documents too fragile to be handled.
While written history, recordkeeping, and literary works have been around for several millennia, paper offered both the lightweight quality of papyrus and parchment with the permanence of clay tablets, all of which had been used in the area between modern-day Iraq and Samarkand that became known for paper technology and manufacturing. Clay tablets, while more permanent and also less sensitive to humidity than papyrus and parchment, were cumbersome and heavy. Ink could be easily erased by scraping it from papyrus and parchment, allowing for contemporaneous and much later changes to be made to documents almost invisibly and allowing for the erasure of certain histories.
Paper often has sizings applied, which are substances applied to paper to change the absorbency. Even with sizings applied to prevent too much ink being absorbed, paper would tear before the ink could be successfully removed, leaving evidence of attempted manipulation. This is because paper, even with sizings, absorbs ink; whereas ink sits on the surface of papyrus and parchment.
Now materials like papyrus, parchment, paper, and anything else that anyone would want digitized, can be subjected to sophisticated digital manipulations that cannot be discerned easily, bringing the issues of papyrus and parchment back to paper. On physical paper, even with the use of graphite, erasures and changes are still often visible. I suggest that perhaps the future of digitization lies in the metaphorical properties of paper that allow changes to be made visible to better track history.
Miriam Santana (PhD student, Department of English)
For this semester, my project has focused on recovering the presence of black people and characters in early Mexican American literature by placing them in critical conversation with colonial archival manuscripts. This was my attempt to imagine Black life as more than what these novels give us access to. Now that’s not to say that these colonial archives don’t come with their own silences and omissions, but my goal is to supplement these novels with other written texts. Where is black life in a Mexican colonial context? Voice? Body? Name? And location?
I chose manuscripts from the Black Diaspora Miscellaneous folder for their content, but also because they make a reasonably-sized collection. The selected manuscripts are documents by the Spanish crown that required all free people of African descent in colonial Mexico to pay a tax based on their African ancestry. It was the first time I worked with archival material that had yet to be digitized. I wanted, in the span of the semester, to choose something that was feasible and that wasn’t overwhelming. My research process following the following steps:
Digitize the selected manuscripts using a flatbed scanner. The scanner turned the manuscripts into PDF files.
I used Transkribus to apply optical character recognition (OCR) to the PDF. I used a model, created by LLILAS Benson digital scholarship coordinator, Albert Palacios, to perform this OCR.
I took the text and inserted it into a Word document. In that Word document, I removed numbers and corrected for dashes, so that I was only left with the bare text.
I used NameTag. NameTag is an open-source tool for named entity recognition (NER). NameTag identifies proper names in text and classifies them into predefined categories, such as names of persons, locations, organizations, etc.
I took that table of information and entered it into an Excel spreadsheet, which resulted in a dataset of names and locations of people rendered in the manuscripts.
In a future project, I aim to follow the same process, with all of the manuscripts in this collection. I hope that it will result in a large dataset of names and places spanning the 18th and 19th century. I plan to create metadata for this collection and use the dataset to create a StoryMap. My hope is that this map represents the lasting and enduring presence of black life in these Mexican colonial archives. Below are some lingering questions that I will continue to think deeply and critically about:
What are the ethical ways of working with these colonial documents?
How do we then think about representation in a way that is ethical?
How do I make sense of my own bias and desire to represent?
How do I think about consent when the people who are in these collections are not alive to give consent?
Natalya Stanke (Dual master’s degree student, iSchool & Center for Middle Eastern Studies)
In our first symposium session as a cohort, we unpacked the term “digitization” to understand the various facets of the digitization process. Taking an iPhone snapshot or scanning a document in a flatbed scanner can be useful; however, it’s ultimately only one step in the entire process of digitization. It’s important to keep in mind the many layers of labor involved from physical examination, image capturing, file processing, metadata description, repository ingestion, and more. It’s also important to continually learn about how to approach workflows of digitization both thoughtfully and equitably.
For this symposium, I chose one book from UT’s library collections and imagined how I would approach this item in a professional setting for digitization. My book is titled Quitábuca or “Your Book” from the original Arabic. It was written by a Syrian priest living in an Arab diaspora community in Sao Paulo, Brazil. The book is written in Arabic and consists of a collection of personal essays, published articles, letter correspondence, and opinion pieces from a variety of publications around the world. It contains biting commentary on French colonialism in the Levant, personal stories about immediate family members, guest author pieces discussing politics, organizing documentation for civic diaspora groups, and more.
First, current American/English-language standards for describing diverse materials with global interconnectedness are insufficient at capturing the richness of the material reflected.
Second, multilingual metadata is the future! Multilingual English/Arabic description (or Arabic/English/Portuguese, in this case) for materials like this book need to be prioritized for institutions seeking to maximize equity of digital dissemination when publishing collections online. I understand this is massively labor-intensive, but limiting the vast majority of rich metadata to the English-speaking world limits the discoverability and accessibility of many relevant materials.
In particular, the interconnectedness of different geographic and cultural regions sparked my curiosity about how to describe this book with useful metadata. When contemplating the description portion of digitization, I ended up with two major (and related) takeaways:
Overall, this was a fun exploration for thinking through professional challenges in digitization and how labor-intensive, but important, it will be to include multilingual and multicultural approaches to my future work in librarianship.
In summer 2023, the UT Libraries invited applications from UT Austin graduate students to participate in a community symposium program centered on developing thoughtful and reflective research and digitization practices. The symposium program aims to create a cohort of UT Austin graduate students engaged in critical reflections on collection development, research practices, and digitization, and the potentialities for reparative work within all of these spheres. The program is called “The Theory & Practice of Digitization Community Symposium” and it is co-sponsored by the UT Libraries and the Andrew W. Mellon Fellowship for Diversity, Inclusion & Cultural Heritage at the Rare Book School.
Eight UT graduate students were selected to participate in the program cohort. The students–in MA and PhD programs–are studying in the African & African Diaspora Studies, English, History, and Middle Eastern Studies departments, as well as in the UT iSchool. They have a variety of experiences with research in libraries and archives, with digitization, and with publishing scholarship, all of which they bring to their cohort discussions. However, they are united to realize the goals of this symposium program, which include reading about, discussing, and creating approaches for research and collection development in a digitizable environment. The latter can be described with the question: what does it mean to create or select print and electronic content in an environment in which digitization is possible and high quality; in which there is support for the applications of machine-readable text; and in which the materials are stewarded by libraries and used by researchers outside of the materials’ region of origin?
The Theory & Practice of Digitization cohort, with Dale J. Correa and Beth Dodd.
Cohort participants are encouraged to engage with existing writing (scholarly and popular) on these topics in thoughtful and critical ways, with the end goal being to create a sense of belonging to the conversation. What gets digitized and how it gets digitized are decisions that affect everyone, but most of all, marginalized communities that have been historically disadvantaged from participation in scholarship and the building of library collections (even, and especially, collections for which they are the subject). As part of this program, cohort participants are trained in the basics of scanning, OCR, and outputs/applications with a material selection of their choice, so that they have insight into the hands-on processes of digitization and how to use this technology for their goals. The program’s culminating public symposium puts the cohort’s theoretical and practical experiences in conversation with a digital cultural heritage scholar and engagement with the audience in order to realize new approaches to digitized resources.
I developed The Theory & Practice of Digitization Community Symposium Program as the final project for my Mellon Fellowship for Diversity, Inclusion & Cultural Heritage at the Rare Book School. As fellows, we are asked to put together a community symposium at our home institution that advances understanding of cultural heritage, archives, and/or special collections and allows us to promote aspects of our collections to broader publics and communities. With the development of the new Scholars Lab at the Perry-Castañeda Library, and considering my own interests in reparative and restorative practices in librarianship and scholarship, I wanted to create an opportunity for graduate students to expand their researcher skill-sets and build reflective approaches to their future professions. We are incredibly fortunate to have a wide range and depth of expertise at the UT Libraries, and it is from this well of experience and insight that this program has drawn.
Our first session, held at the end of August shortly after the semester began, featured a conversation with Rachel E. Winston (Black Diaspora Archivist at the Benson Latin American Collection) and Beth Dodd (Curator at the Alexander Architectural Archives) on defining terms for our work in this program through their experience with digitization as archivists at UT. Rachel and Beth presented on the process of selecting and adding items to the archives, including when, how, and why they make decisions around digitization. Their experiences with a variety of collections––from donors or vendors; recent or older; created in the U.S. or around the world––gave them insight to respond to students’ questions regarding the ethics of archival digitization and stimulated the students’ engagement with crucial concepts by providing real and tried examples for them to consider.
TPD cohort session #1 with Rachel E. Winston and Beth Dodd in the PCL Learning Labs,
The program’s second session introduced students to the basic principles of handling cultural heritage materials and digitizing them. My colleagues from the UT Libraries’ Stewardship department, Brittany Centeno (Preservation Librarian) and Kiana Fekette (Head of Digitization) led the students through a review of best practices for handling paper materials such as books, periodicals, and personal archives. The session was held in the new Scan Tech Studio in the Scholars Lab, which functions as a self-service facility for independent researcher digitization, image processing, and text recognition-based scholarship. Brittany and Kiana brought sample materials so that the students could get a sense of what to do for for different preservation situations, such as a book with a broken spine, brittle and flaking paper or leather, bent or misshapen items, and materials that are tightly bound. They also demonstrated how to use a diffuser light set up, which can be particularly useful for items with a difficult-to-capture sheen (such as different types of photographs) or for mobile applications when traveling for research.
TPD cohort session #2 with Brittany Centeno and Kiana Fekette in the Scan Tech Studio.
In our third session, we met with Allyssa Guzman (Head of Digital Scholarship Services) and Ian Goodale (European Studies Librarian) for a survey of, training with, and discussion of tools that the students might use for their research with digitized materials. Allyssa covered how to get started with digital scholarship, including project planning/management and tool selection. She created an excellent LibGuide for the cohort to refer back to as they move forward with their work. Ian reviewed a number of tools that we recommend and regularly use here at the UT Libraries for transcription/OCR correction and text analysis, including some that he has developed himself.
TPD cohort session #3, with Allyssa Guzman in this image.
The cohort’s efforts will culminate in a community symposium on November 9, 2023, 5 – 7 PM in the PCL Scholars Lab Data Lab. This event is free and open to the public: everyone is invited and encouraged to attend. The symposium is an opportunity for the UT, Austin, and greater central Texas communities to learn about the digitization of cultural heritage through the experiences of the student cohort members. It’s also an opportunity to hear from a respected scholar of digital cultural heritage, Dr. Raha Rafii, who will be giving the keynote address. Her lecture, titled, “Navigating the Ethical Landscape of Manuscript Digitization,” will look at recent examples of digitized forms of cultural heritage and the impact on their origin communities in order to think through complex issues of ethics, and to determine the lines between academic researcher priorities and digitization as an extension of colonial and imperialist practices. For more information on the community symposium, please see the UT Libraries’ Events page.
Next year, I’ll have been a librarian for 10 years, and there are many things that I’ve come to learn and appreciate in my time in the profession. I’m a subject specialist, the liaison librarian for Middle Eastern Studies at UT Austin. I manage library services for researchers interested in the Middle East as well as collections from or about the Middle East. I also coordinate services and collections for the History department. Both roles have allowed me to consider and question the boundaries that researchers and librarians alike have maintained regarding the types, priority, and value of library collections, particularly our physical collections. While all cultural heritage has value, it is usually what we call special collections or rare books that are the most highly prized. They tend to cost more, there are fewer of them, and they require special handling because of their age and/or material. Special collections are often stored in a separate and distinct space, served by dedicated and highly trained personnel, and permitted for use in controlled circumstances. What happens, however, when a valuable, rare item is kept in the regular stacks of the library’s general collections? How did it get there and why would a librarian keep it there? I want to explore these questions with two examples from the Middle East collections at UT Libraries that have allowed me to design new approaches to teaching and learning with the special collections in our stacks.
Dale J. Correa reviews the holdings at Turkish vendor Librakons in Istanbul.
In summer 2022, I had the honor to represent UT Libraries on an acquisitions and networking trip in Istanbul and Ankara, Türkiye. I met with a private collector in Istanbul, to whom I had been introduced by one of our regular Türkiye vendors, and purchased a number of titles in Arabic that had been published in Egypt. (It is perhaps curious that I’d go looking for Arabic in a country where the principal language in Turkish, and I’ve written about how and why I do this here.) One of those titles was al-Fath: Sahifah Islamiyah ‘Ilmiyah Akhlaqiyah, an intellectual journal circulated in the early 20th century. This journal is a crucial, backbone source for the intellectual, political, and legal history of the Middle East. It covers a variety of topics, including modernist Islamic thought, modern Egyptian history, Arabic language, British colonial history, Palestine and Zionism, Ottoman history, ethics, and the moral landscape of early 20th century Egypt. It is often cited by intellectuals of its time period (indicating its contemporary import), but it’s not widely available for research consultation in North America . Although North American scholars—including several at UT Austin in the departments of Middle Eastern Studies and History––have seen this title cited, and desired to consult the periodical themselves, many have been unable to do so. Only three North American institutions, including UT Austin, can claim to have a complete copy, while a handful of others have some volumes but not others. Considering the journal was published from 1926 – 1948, such spotty coverage is often inevitable. Additionally, al-Fath has not been digitized (which runs contrary to the growing researcher expectation for the digital availability of such essential materials).
When I brought al-Fath to the UT Libraries, I knew there would be a significant community of interest around it and that it would be an ideal locus for scholarly exchange. I partnered with Dr. Samy Ayoub (Department of Middle Eastern Studies and the UT School of Law) to prepare and host a reading workshop on al-Fath for faculty and graduate students in January 2023. Over the course of the fall semester, the UT Libraries’ Content Management department was able to complete the description and processing of al-Fath, getting it into the stacks in record time for researchers. This gave Dr. Ayoub and me time to prepare for the workshop with the help of Dr. Ahmad Agbaria (the Schusterman Center for Jewish Studies), who specializes in 20th century Arab intellectualism. While these two faculty members selected passages and legal cases for workshop attendees to read and interpret, I prepared a display of contemporary periodicals from our collections to provide greater context and comparison for al-Fath.
The book display at the al-Fath workshop.Dr. Samy Ayoub introduces the workshop.Workshop attendees use an iPad as a document reader, sharing their text on the screens of the Learning Lab.
At the one-day workshop, faculty and graduate students with advanced reading knowledge of Arabic came together to unearth the treasures of this periodical for a new audience. Dr. Ayoub introduced the conceptual framework of the workshop and the thinking behind the selection of passages to read. Dr. Agbaria provided an excellent introduction to the scholarship of the period and the biography of al-Fath’s founding editor, Muhibb al-Din Khatib. I took the attendees through the acquisitions process for this title and introduced contemporary works from our collections, demonstrating the great company that al-Fath keeps in the stacks. These titles include Akhir Sa’ah, al-Qiblah (another journal edited by Khatib),Jaridat al-Balagh al-Usbu’i (a selection of which is now part of UT Libraries’ Digital Collections), and al-Muqtataf. We then spent the morning reading passages together, taking turns leading the discussion. For the afternoon session, we divided into small groups to read reports of legal cases and then share out our analysis with the others.
The magazine Akhir Sa’ah.Dr. Hina Azam works with Middle Eastern Studies graduate students.Middle Eastern Studies and History faculty consult on a text together.
The workshop’s attendees walked away with a greater understanding of 20th-century Arab scholarship and legal thinking, and intimate familiarity with a (new-to-them) text that they can use in their teaching and research. Even faculty who have been with the university for most of their careers learned from the introductions and book display about materials helpful for their research that they hadn’t known were in our collections. The graduate students had the essential experience of close-reading a text in Arabic, which is a skill that they will need for their thesis and dissertation research . In many ways the workshop followed a classic philological approach by focusing on reading a text. However, through collaboration, and by combining the expertise of scholars 1) in a range of fields within the discipline of Middle Eastern Studies and 2) of different experience levels, we were able to read al-Fath in its own context, building the bigger picture against which to lay our understandings of discrete intellectual and political trends.
Banking on Ephemera
Before the pandemic, I began accepting donations of Middle East banking and finance materials: pamphlets, brochures, reports, and guides. These formats are the kind usually produced only once as an annual bank report, or a visitor’s guide to a financial institution that would’ve been updated regularly (and the outdated copies destroyed). For their impermanent nature, they are known as “ephemera” in the library world. They are inherently rare, as they were produced only once and in limited numbers. On top of that, most people would probably dispose of such materials in their personal possession. Think about the last time that you visited a tourist site and received a map or brochure––did you keep it? If you did, had it been folded or creased, beaten up at the corners from use? To find such materials at all, and then to find them in pristine condition, is rare indeed. I am sincerely grateful to the donor, UT Austin Emeritus Professor of Government Clement Henry, for his generous gift, which has made UT Libraries a destination for research on Middle East banking in the 20th century.
The Middle East Banking exhibit in the PCL Scholars Commons (relocated to the UFCU room).A close-up of the bank reports in the Middle East banking exhibit.
In accepting the gift of these materials, I recognized that they would be something to advertise widely to increase their accessibility. The UT Libraries’ Digital Stewardship department created superb images of some of the donated materials, as well as of some of our existing Middle East bank-related holdings, which I was able to turn into a digital exhibit. I also had the opportunity to build a physical exhibit in the Perry-Castañeda Library Scholars Commons, which was on view from November 2022 – March 2023. The physical exhibit featured some materials from the digital exhibit, and a number of other items that are better appreciated in person. One of those items is a map of the Turkish Central Bank branches and country infrastructure in the Central Bank’s 1955 annual report. A bank report is probably not the first place a researcher would think to find a map of Turkish financial and transportation infrastructure, which is why I wanted to highlight these materials for researchers at all levels of experience. My role as librarian is to make critical connections between researchers and the materials that will make a difference for their scholarship, and my day-to-day observations from our collections are essential for that work. The digital and physical Middle East banking exhibits were ways that I could demonstrate the scholarly utility of ephemeral, often neglected materials such as these.
Poster advertising the exhibit launch lecture with Dr. Clement M. Henry.
To honor the launch of the exhibits and the efforts of Dr. Henry to donate his incredible personal research collection to UT Libraries, the UT Libraries hosted a lecture by Dr. Henry titled, “Banks in the Political Economies of the Middle East and North Africa.” I sought to build upon the exhibits and Dr. Henry’s lecture by holding two “study hours” in the days preceding the main lecture event. Partnering with faculty in the Department of Middle Eastern Studies, I brought two advanced undergraduate courses into the Perry-Castañeda Library Learning Labs to physically engage with our Middle East banking collection. I pulled a selection of materials that I hoped would be fascinating and created an exercise for the students to do in small groups. A tangential benefit of the Middle East banking collection is that it is in English, French, Arabic, Persian, and Turkish, and comes in a variety of formats from monographs to pamphlets to serial reports. There’s a little something for everyone, and language does not need to be a barrier to understanding. This was the intention of the original authors of the bank reports and pamphlets, of course, who sought to broaden the investor base of their institutions.
As primary sources, these materials represent a period of rapid change and interaction with the conceptualizations and implementations of the term “modernity.” Students in two very different courses on the contemporary Middle East were able to handle these rare and special ephemera and consider such issues as: choice of language(s); paper quality; color versus black and white images; length; frequency of publication; and choice of topics covered in the material (some of which were quite political). At a time when many students engage with library collections in a primarily digital form, and often with secondary sources that may only summarize the primary essence of the research, these study hours became precious moments for students to connect with the different, unfamiliar medium of ephemeral print and determine for themselves what it signifies to have access to these materials.
Keeping Special in the Stacks
So what happens when a valuable, rare item is kept in the regular stacks of the library’s general collections? It gets used and appreciated. Researchers access it more readily, students can stumble upon it while working on a term paper, and the item itself remains in a context of similar and complimentary works. It adds value to its shelf and stacks row and makes exploring the floors of the university library that much more interesting. There is almost no barrier to access, particularly in the public university environment of UT Libraries, and so even the most novice of researchers has a chance to benefit from this material. As Middle Eastern Studies Librarian, I intend to keep adding special and rare materials to our collection, not simply or only as a means of distinguishing the UT collection from others, but also because it is possible and currently a beneficial practice to make these materials available to all researchers who walk in our doors. I believe that the value of these items exists in the perceived tension between their rarity and their easy physical access, and I ask readers of this blog post to reconsider the hierarchy of rare and general collections.
Dale J. Correa, PhD, MS/LIS, Middle Eastern Studies Librarian & History Coordinator, University of Texas Libraries
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the UT Libraries Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of, and future creative contributions to, the growing fields of digital scholarship.
While digital, machine-readable texts in Arabic are growing in their availability, certain genres of writing and scholarship in Arabic have become more readily accessible than others. Among those more obscure disciplines are Sufism, theology (Muslim and Christian), and philosophy. These tend to be theoretically complex, and even dogmatically challenging, disciplines that are not as well represented in North American Islamic Studies programs as literature or Qur’anic studies. The Nuṣūṣ corpus––a project led by Antonio Musto––seeks to fill in some of the desiderata by putting more texts from these essential disciplines up on the Internet for researchers to use.
A project that began with an almost exclusive focus on Sufism, Nuṣūṣ has expanded to include works from a variety of complex disciplines of Arabic-language scholarship produced by Muslims and Christians. The corpus currently contains 61 machine-readable texts, with plans to add more and to make the text files available for download. Differing from other, larger corpora of Islamicate[1] disciplines, Nuṣūṣ provides the bibliographic information for the modern editions from which these digitized texts are derived. This is not only a responsible move, but a useful one for researchers: modern editions of historic texts can differ greatly; comparing modern editors’ approaches to the text and their choices that affect meaning and understanding is therefore rich area of exploration in Arabic-language digital humanities. It is hoped that––as possible––Nuṣūṣ will start to add multiple editions of historic texts in order to facilitate this comparative work.
Nusus’s “Browse Corpus” page.
Nuṣūṣ’s aspirations lie in providing researchers with an adequate corpus from which to do computational text analysis. To that end, the team has created several different ways for researchers to access and engage with the texts. The “Browse Corpus” feature gives researchers an accurate sense of which specific items are included. If one is looking for a particular author or text, this would be the list to consult. This is also where crucial metadata (information about the item) is located, such as the origin of the digital images (Nuṣūṣ’s own OCR process or the OpenITI project repository), the internal corpus text ID, the date of the historic text’s alleged composition, the discipline, the genre of writing, the title, and the author. Author names link to biographies from the Encyclopaedia of Islam, and titles link to the WorldCat record for the modern edition used in the digitization of the text.
Performing a search for the exact term “عقل” in the Nuṣūṣ corpus.
Furthermore, the Nuṣūṣ team has provided a cross-corpus search tool. Researchers can build a search using the provided fields and Boolean operators (AND, OR), and can specify whether they are searching for an exact term. It is also possible to confine the search to specific titles, authors, or genres. This arrangement encourages researchers to pursue projects that might compare across a scholar’s oeuvre, across a genre of writing (Muslim theology, philosophy, Sufism, or Christian theology), or across a single text. Researchers could use this tool to construct searches across known networks of scholars, as well. As the corpus expands, the ability to conduct searches and collect the resulting data will become increasingly effective and useful.
Readers interested in text and corpora analysis should consult the UT Libraries’ Digital Humanities Tools and Resources guide for more information on methods to apply to corpora like Nuṣūṣ. For recommendations of other corpora that might be useful for your research, consult the Data Set list on the Text Analysis guide. Lastly, as the Nuṣūṣ corpus partners with and derives from the OpenITI repository, it is worth considering the OpenITI repository documentation at the KITAB project. Happy corpus hunting!
Dale J. Correa, PhD, MS/LIS is Middle Eastern Studies Librarian andHistory Coordinator for the UT Libraries.
[1] The term Islamicate was coined by Marshall G.S. Hodgson in volume 1 of his The Venture of Islam (p. 57).
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the UT Libraries Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of, and future creative contributions to, the growing fields of digital scholarship.
A perennial issue for digital researchers in non-Roman-script languages (e.g., Arabic, Hebrew, or Ancient Greek) is the availability and utility of tools for automatically transcribing digitized text. That is, how can researchers make their print and handwritten materials, or digitized print materials, machine-readable, full-text searchable, and ready for numerous digital scholarship applications? Although emerging a little later than their Roman script peers, such tools have been under development for some time for non-Roman languages––and often with marked improvements over their digital brethren. One of the most remarkable tools developed to date is eScriptorium, an open-source platform for digitized document analysis. It makes use of the Kraken Optical Character Recognition (OCR) engine, which was developed to address the needs of right-to-left languages such as Arabic.
While the purpose of eScriptorium is to provide a holistic workflow to produce digital editions, the first step in the process is the transcription of primary sources, and this is where the project has been focused until recently. Researchers can train the tool to machine-transcribe texts according to their needs. It has been designed to work with books, documents, inscriptions––anything that has been rendered into a digitized image. Adding such images to eScriptorium is the first step in the transcription process. As more and more libraries and archives make digital surrogates of printed and handwritten texts freely available on the Internet, researchers have ever-increasing opportunities to explore texts and create useful data for their research. eScriptorium has been designed to work especially well with handwritten texts, which means that it generally will work even better with printed texts. eScriptorium, as a tool, has the added benefit of working with the International Image Interoperability Framework (IIIF). This means that researchers can access images at a variety of institutions around the world directly and without the necessity of downloading and hosting those materials themselves. IIIF also facilitates the automatic import of available metadata with images, which can be a big time-saver.
eScriptorium’s IIIF import interface and process.
Viewing and editing metadata from a IIIF import in eScriptorium.
The second step in eScriptorium’s transcription process is line detection. eScriptorium can be used to annotate images of documents, show where lines of text are, and which areas of a page or image to transcribe––all as customized by the researcher. Researchers create examples of what they want the computer to do, and the tool learns from those examples. It then automatically applies its learning to other images. eScriptorium has a default system that can detect the basic layout of pages, and––thankfully––researchers can modify the results of the default line detection in order to improve the final result of transcription.
A closer view of how researchers can adjust eScriptorium’s default detection of lines.
Once the lines have been identified, researchers move on to the transcription itself. Researchers define the transcription standards (normalization, romanization, approaches to punctuation and abbreviation, and so on). The tool learns from transcription examples created by the researcher and applies what it learns to the added texts. With eScriptorium, researchers can type the transcribed text by hand, import an existing text using a standard format, or copy and paste a text from elsewhere. After creating enough examples (an undefined number that will differ for each researcher’s needs), the tool learns from them and then can transcribe the remaining texts automatically. Some correction may be needed, but those corrections can then be used to train the tool again.
Using a trained model for transcription in eScriptorium; researchers can zoom in line by line to make corrections.
Of note is how eScriptorium has been selected for an essential role in the Open Islamicate Texts Initiative’s Arabic-script Optical Character Recognition Catalyst Project (OpenITI AOCP). It will be the basis of the OpenITI AOCP’s “digital text production pipeline,” facilitating OCR and text export into a variety of formats. eScriptorium encourages researchers to download, publish, and share trained models, and to make use of trained models from other projects. OpenITI AOCP and eScriptorium-associated researchers have published such data, including BADAM (Baseline Detection in Arabic-script Manuscripts). Researchers can even retrain other trained models to their own purposes. This can help researchers get going with their transcription faster, reducing the time needed for creating models by hand.
I encourage readers to consider using UT Libraries’ own digital collections (particularly the Middle East Studies Collection) as a source of digitized images of text if they want to give eScriptorium a try. UT Libraries also has worked closely with FromThePage, a transcription tool for collaborative transcription and translation projects. The crowdsourcing and collaborative options available with FTP will be useful to many projects focusing on documents too challenging for the capabilities of today’s OCR and HTR tools. Don’t forget to share your projects and let us know how these tools and materials have helped your research!
Dale J. Correa, PhD, MS/LIS is Middle Eastern Studies Librarian andHistory Coordinator for the UT Libraries.
Read, hot & digitized: Librarians and the digital scholarship they love — In this new series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
Over the years of my involvement in Middle Eastern and Islamic Studies (MEIS), I have become something of an advocate for learning modern Turkish. The necessity of facility with Turkish in order to conduct research in MEIS, and more importantly, to carry on scholarly communication in MEIS, grows clearer every year. I would not hesitate to argue that non-Turkish scholars ignore Turkish scholarship at their own peril—it is that central, plentiful, and informative. An excellent example of a scholarly development out of Turkish academe that would be quite useful for MEIS pedagogy and research is İslam Düşünce Atlası, or The Atlas of Islamic Thought. It also happens to be an incredible digital Islamic Studies scholarship initiative.
İslam Düşünce Atlası (İDA) is a project of the İlim Etüdler Derneği (İLEM)/Scientific Studies Association with the support of the Konya Metropolitan Municipality Culture Office. It is coordinated by İbrahim Halil Üçer, with the support of over a hundred researchers, design experts, software developers, and GIS/map experts. The goal of the project is to make the academic study of the history of Islamic thought easily accessible to scholars and laypeople alike through new (digital) techniques and within the logic of network relations. İDA has been conceived as an open-access website with interactive programs for a range of applications. Its developers intend it to contribute a digital perspective to historical writing on Islam: a reading of the history of Islamic thought from a digitally-visualized time-spatial perspective and context.
The timeline, noting architectural, historical, intellectual, and institutional events.
İDA features three conceptual maps that aim to visualize complex relationships and to establish a historical backbone for the larger project of the atlas: the Timeline (literally time “map,” which is a more signifying term for the tool, Zaman Haritası), the Books Map (Kitaplar Haritası), and the Person Map (Kişiler Haritası). It also proposes a new understanding of the periodization of Islamic history based on the development of schools of thought (broadly defined) and their geographic spread. İDA endeavors to answer several questions through these tools: by whom, when, where, how, in relation to which school traditions, through what kinds of interactions, and through which textual traditions was Islamic thought produced? Many of these questions can be summed up under the umbrella of prosopography, and in that arena, İDA has a few notable peer projects: the Mamluk Prosopography Project, Prosopographical Database for Indic Texts (PANDiT), and the Jerusalem Prosopography Project (with a focus on the period of Mongol rule), among others.
The book map, focusing on felsefe/philosophy and the connections among famous works.
One of my favorite aspects of İDA is the book map and its accompanying introduction. The researchers behind İDA do their audience the great service of explaining the development and establishment of the various genres of writing in the Islamic sciences. Importantly, they also link the development of these genres to the periodization of Islamic history that they propose. The eight stages of genre development that are identified—collation/organization, translation, structured prose, commentary, gloss, annotation, evaluative or dialogic commentary, and excerpts/summaries—share with the larger İDA project their origin in scholarly networking and relationship building. By visualizing the networks of Muslim scholars, as well as the relationships among their scholarly production and the non-linear, multi-faceted time “map” of Islamic thought, İDA weaves together the disparate facets of a complex and oft willfully misunderstood intellectual tradition
The person map, in this snapshot highlighting the intellectual and pedagogical connections to and from the renowned scholar Abū Ḥāmid al-Ghazālī/Gazâlî.
I encourage readers not only to learn some modern Turkish in order to make full use of İDA (although Google translate will work in a pinch!), but also to explore threads throughout all of the visualizations: for example, trace al-Ghazālī’s scholarly network, and then look at that of his works. What similarities and differences do you notice? Is there a pattern to the links among works and scholars? Readers who are interested in the intellectual history of Islam should check out my Islamic Studies LibGuide, as well as searches in the UT Libraries’ catalog for some of their favorite authors (see here for al-Ghazālī/Ghazzālī, Ibn Sina/Avicenna, and Ibn al-Arabi).
Read, hot & digitized: Librarians and the digital scholarship they love — In this new series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
“Translatio” at the University of Bonn—a project of the Department of Islamic Studies and Middle Eastern Languages—seeks to make Arabic, Persian, and Ottoman Turkish periodicals published between 1860 and 1945 available online for free. The periodicals are selected from a number of partner institutions and digitized at the University of Bonn. The digital surrogates are then made available in a readable and downloadable version through the University’s digital collections website. “Translatio” strives, in its first phase, to focus on digitizing complete or mostly complete runs of periodicals (although it is evident that some of the titles are not nearly complete; UT Austin has acquired and is processing a complete set of al-Ḥurriyya, although there is only one volume extant in the “Translatio” database). The next phase will likely turn to less complete and single issues of periodicals that still bear cultural, historical, and research significance. The current collaborators include Bamberg University Library, Oriental Seminar of the University of Freiburg, Mainz University Library, Bavarian State Library Munich, Tübingen University Library, and the University of Bonn. Although “Translatio” is not a digital scholarship project in the conventional sense, it is still a novel gathering of digitized Middle Eastern periodicals that offers tantalizing opportunities for researchers engaged with traditional and digital methods.
Access to the digitized periodicals is quite user-friendly: they are organized by language group, and then alphabetically by title. Each title expands into a brief description of the periodical (in German), a short bibliography when available, and a link to the digital images. Transliteration follows the German standard, and metadata fields are indicated in German. Some understanding of German, therefore, is helpful for navigating the site and the contents of the periodicals (Google Translate, alone or via the Chrome browser, works well in this case). The metadata for each periodical is given at the title level, and users can click through individual issues to see issue-level metadata. The metadata does not include information on editors and authors, which would be desirable for researchers, but would also take an incredible amount of labor on the side of the project workers. This could be an area for future development.
As for the digital images of the periodicals: they can be downloaded in PDF or JPEG format and saved directly to the user’s device. The images are of adequate quality for researchers who wish to use them much like they would a microform newspaper, by scanning, browsing, and reading. However, the quality of many of the titles is not high enough to capture physical details of the ink or paper, and would not lend itself to optical character recognition (OCR). That is perhaps both the primary frustration and the arena of greatest possibility with this project: all of these digitized periodicals are begging to be put through OCR so that they may be full-text searchable and instrumentalized as a corpus for distant reading. That would certainly be a groundbreaking development for the field of Middle Eastern Studies.
It is, nevertheless, significant that researchers have access to all of these excellent and important Middle Eastern periodicals in one place. Additionally—and this librarian’s favorite aspect of the project—the project website includes a clearinghouse of digital Middle Eastern periodicals collections from institutions around the world. Thus, Bonn’s digitized periodicals do not live in complete isolation from similar efforts on the web; rather, one can use the “Translatio” website as a starting place for research across a number of related collections. Researchers using UT Libraries’ print collections have the opportunity to interact with some of these titles in person as well, including al-Balāgh al-ʿUsbūʿī, al-Bayān, and Sharq, among others. The next step in the evolution of the relationships among these collections would be a federated search across all of them simultaneously—and this librarian would love to see a digital reading interface that observes the right-to-left directionality of all three languages in this project—but let’s take this one step at a time. The “Translatio” team at Bonn has much to celebrate.
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the Libraries’ Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship to encourage and inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
The
Istanbul Urban Database project, headed by Nil
Tuzcu (MIT), Sibel Bozdoğan (İstanbul Bilgi), and Gül
Neşe Doğusan Alexander (Harvard), seeks
to preserve collective memory and the urban cultural heritage of Istanbul by
becoming the most comprehensive online archive of Istanbul’s urban history. The
project is based on a digital corpus of maps of Istanbul, aerial imagery,
photographs, and geographical features. The project combines this wide range of
historical data on a sustainable platform that can be integrated into other
projects. The project does not stand alone; there is, in fact, an API in
development for serving and exporting the various layers of the information it
contains.
With the Istanbul Urban Database, users can
select a variety of maps, photos, and other imagery to superimpose over one
another, or compare. You can examine one historical map at a time, superimpose
them with adjustable transparency, and overlay georeferenced features on the
maps. The side-by-side tool allows users to compare maps from two different
time periods (currently limited to the 19th and 20th
centuries). Uniquely, the project draws on Ottoman and French maps, primarily
from the Harvard Map Collection. This allows the user to get a sense of both
the internal and external views of Istanbul in the early 20th
century.
The map comparison tool.
In terms of infrastructure, the Istanbul Urban
Database’s transportation layer hosts information drawn from a 1922 map on
ferry, train, and tramway lines. The project organizers decided to present
major roads separately because of their impact on city growth. The ferry,
train, and tramway lines, and the roads, were drawn by Harvard Mellon Urban
Initiative researchers––a quite labor intensive process from which
users benefit immensely.
Users also will enjoy having access to Henri Prost’s master plan archives,
which have had significant effect on the development of the city of Istanbul.
Lastly, users can peruse photographs of everyday life at different points in
Istanbul’s history. Examples include beaches, casinos, movie theaters, and
patisseries; snapshots of lives well-lived so long ago, in some cases in places
that no longer exist.
Looking at spaces of everyday life, including beaches and the spaces of Beyoğlu.
The Istanbul Urban Database project is significant for its
combination of resources on an accessible platform with potential for
applications in other projects. Istanbul is a difficult city to navigate, let
alone understand, today, and so attempting to imagine its past lives might seem
rather intimidating for researchers. The Istanbul Urban Database project
streamlines access to crucial 20th and late-19th century
resources to facilitate research on the growth, structure, and development of
the city of Istanbul.
Using the comparison tool between 19th century maps.
I encourage readers to explore all of the tools available,
especially the comparison tool that allows you slide two maps right and left to
compare time periods. I also suggest looking through the photographs of
everyday life that are exhibited through this project, and examine whether or
not these places still exist today by zooming into the base satellite map.
Readers who are interested in maps of Istanbul and Turkey more broadly would
benefit from visiting the UT Maps Collection. The maps of Turkey and specificallyIstanbul are extensive and of interest for those piqued by the Istanbul
Urban Database.


































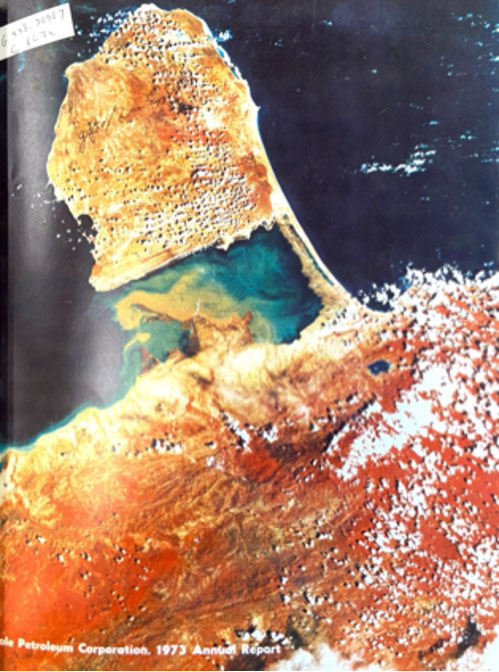




























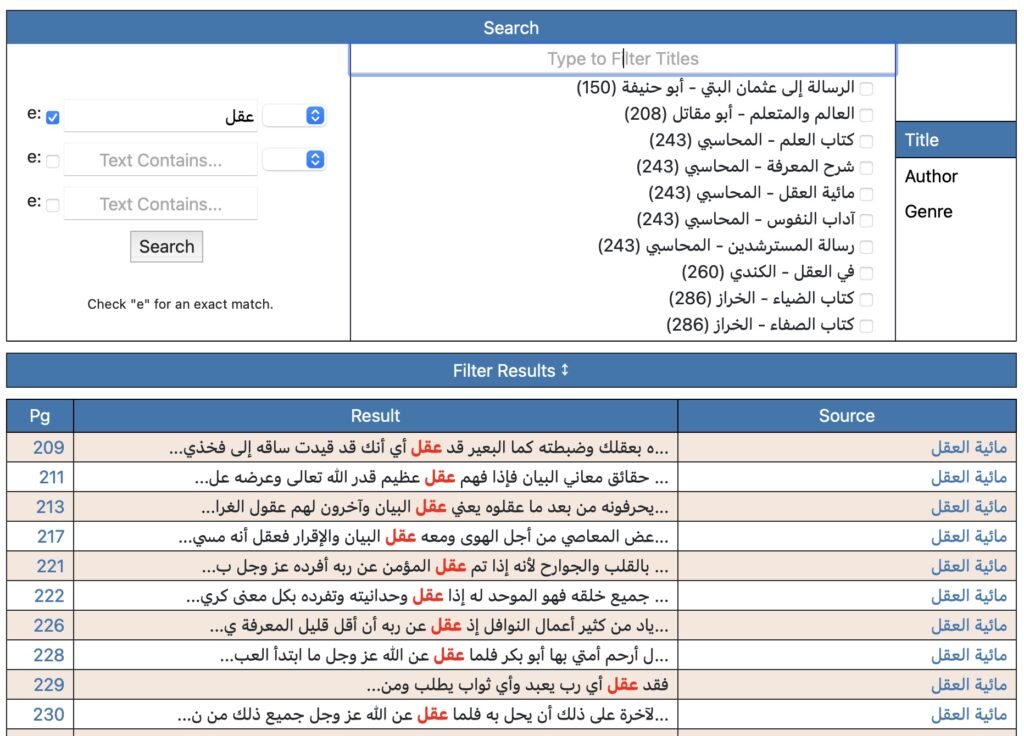



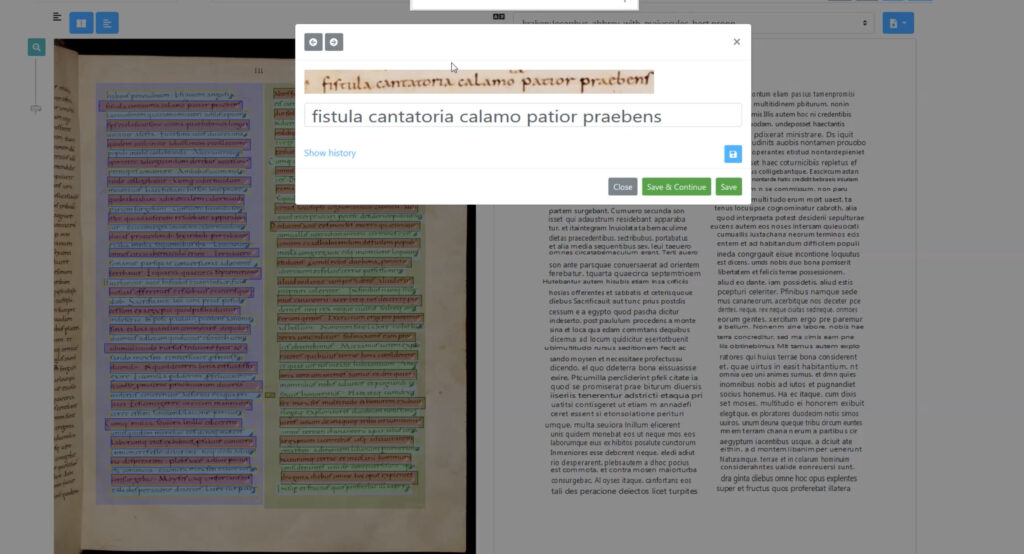

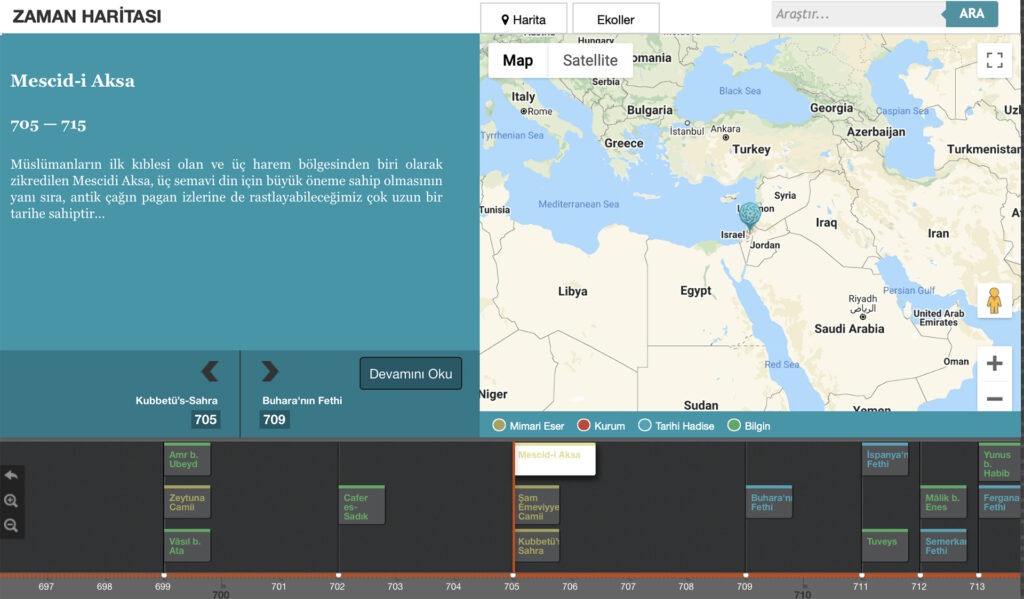
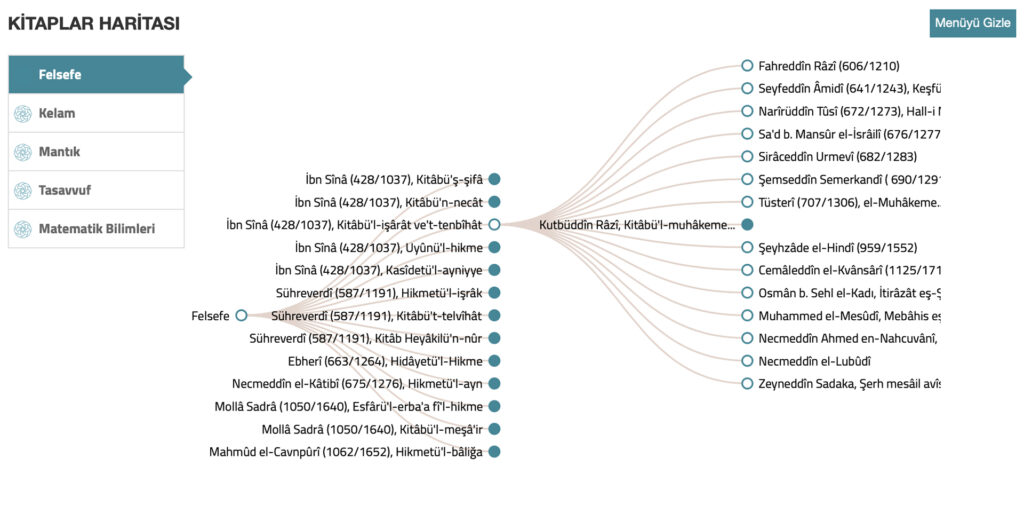
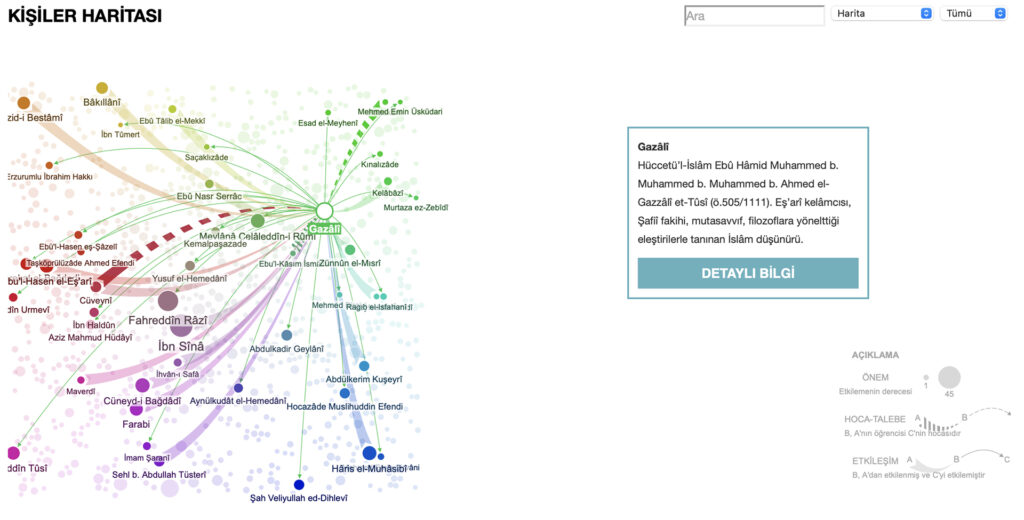




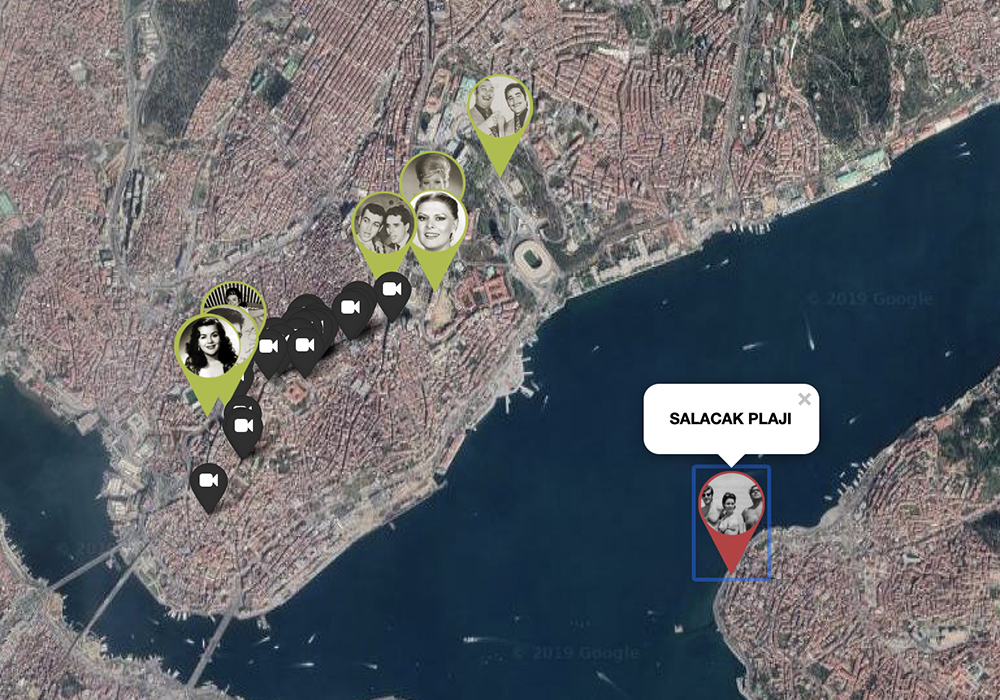
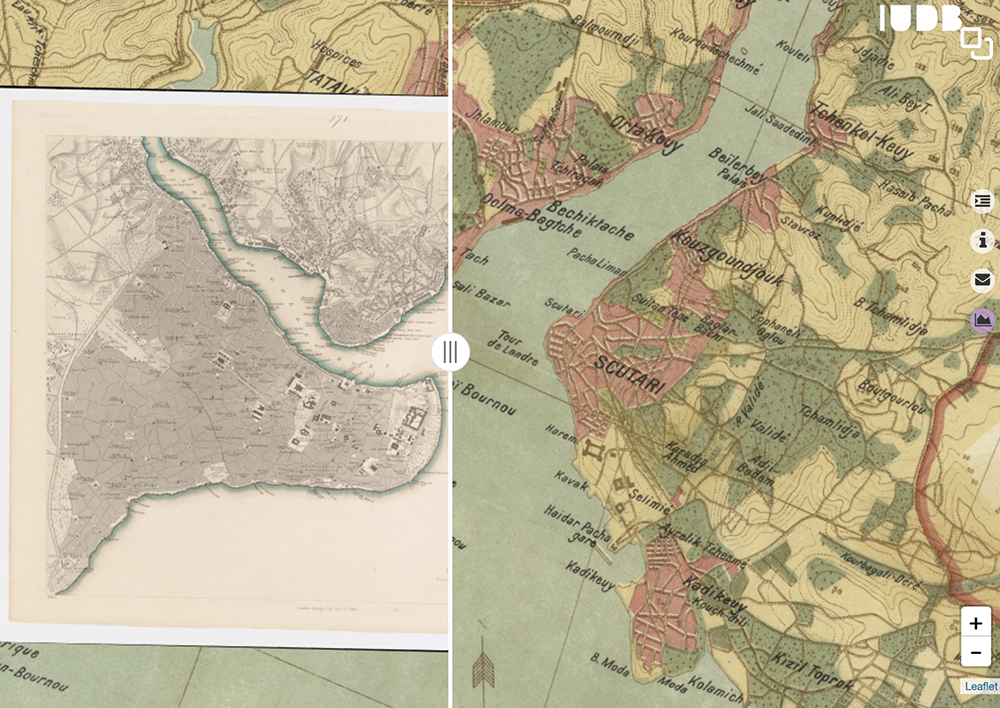
{kind=link}