

Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the UT Libraries Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of, and future creative contributions to, the growing fields of digital scholarship.
A perennial issue for digital researchers in non-Roman-script languages (e.g., Arabic, Hebrew, or Ancient Greek) is the availability and utility of tools for automatically transcribing digitized text. That is, how can researchers make their print and handwritten materials, or digitized print materials, machine-readable, full-text searchable, and ready for numerous digital scholarship applications? Although emerging a little later than their Roman script peers, such tools have been under development for some time for non-Roman languages––and often with marked improvements over their digital brethren. One of the most remarkable tools developed to date is eScriptorium, an open-source platform for digitized document analysis. It makes use of the Kraken Optical Character Recognition (OCR) engine, which was developed to address the needs of right-to-left languages such as Arabic.
While the purpose of eScriptorium is to provide a holistic workflow to produce digital editions, the first step in the process is the transcription of primary sources, and this is where the project has been focused until recently. Researchers can train the tool to machine-transcribe texts according to their needs. It has been designed to work with books, documents, inscriptions––anything that has been rendered into a digitized image. Adding such images to eScriptorium is the first step in the transcription process. As more and more libraries and archives make digital surrogates of printed and handwritten texts freely available on the Internet, researchers have ever-increasing opportunities to explore texts and create useful data for their research. eScriptorium has been designed to work especially well with handwritten texts, which means that it generally will work even better with printed texts. eScriptorium, as a tool, has the added benefit of working with the International Image Interoperability Framework (IIIF). This means that researchers can access images at a variety of institutions around the world directly and without the necessity of downloading and hosting those materials themselves. IIIF also facilitates the automatic import of available metadata with images, which can be a big time-saver.
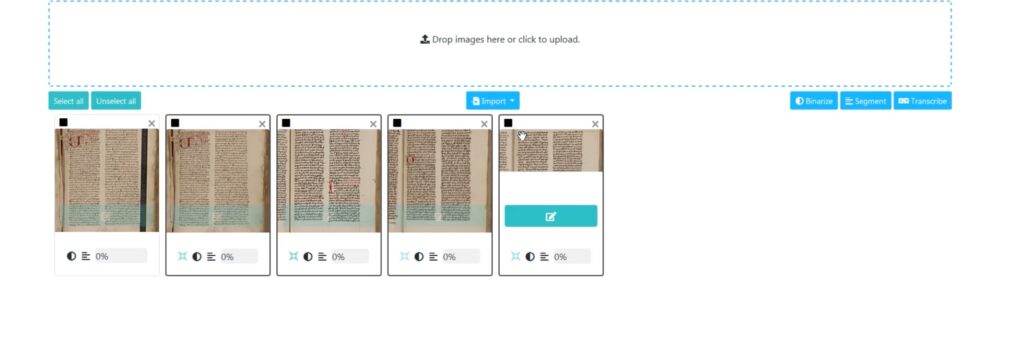
eScriptorium’s IIIF import interface and process.
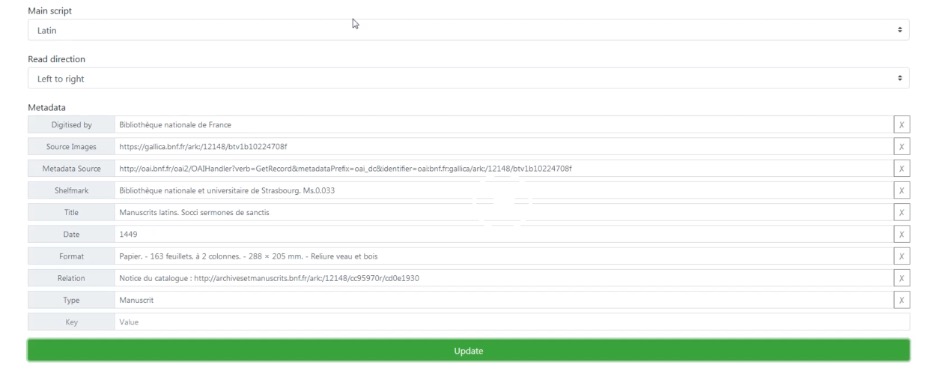
Viewing and editing metadata from a IIIF import in eScriptorium.
The second step in eScriptorium’s transcription process is line detection. eScriptorium can be used to annotate images of documents, show where lines of text are, and which areas of a page or image to transcribe––all as customized by the researcher. Researchers create examples of what they want the computer to do, and the tool learns from those examples. It then automatically applies its learning to other images. eScriptorium has a default system that can detect the basic layout of pages, and––thankfully––researchers can modify the results of the default line detection in order to improve the final result of transcription.

eScriptorium’s line detection and editing interface with a printed Arabic text.

A closer view of how researchers can adjust eScriptorium’s default detection of lines.
Once the lines have been identified, researchers move on to the transcription itself. Researchers define the transcription standards (normalization, romanization, approaches to punctuation and abbreviation, and so on). The tool learns from transcription examples created by the researcher and applies what it learns to the added texts. With eScriptorium, researchers can type the transcribed text by hand, import an existing text using a standard format, or copy and paste a text from elsewhere. After creating enough examples (an undefined number that will differ for each researcher’s needs), the tool learns from them and then can transcribe the remaining texts automatically. Some correction may be needed, but those corrections can then be used to train the tool again.
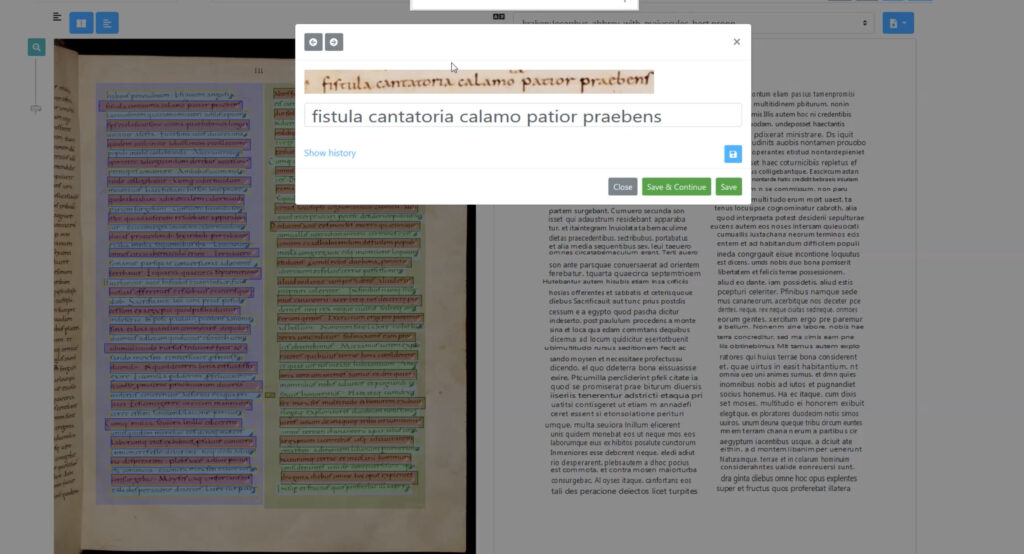
Using a trained model for transcription in eScriptorium; researchers can zoom in line by line to make corrections.
Of note is how eScriptorium has been selected for an essential role in the Open Islamicate Texts Initiative’s Arabic-script Optical Character Recognition Catalyst Project (OpenITI AOCP). It will be the basis of the OpenITI AOCP’s “digital text production pipeline,” facilitating OCR and text export into a variety of formats. eScriptorium encourages researchers to download, publish, and share trained models, and to make use of trained models from other projects. OpenITI AOCP and eScriptorium-associated researchers have published such data, including BADAM (Baseline Detection in Arabic-script Manuscripts). Researchers can even retrain other trained models to their own purposes. This can help researchers get going with their transcription faster, reducing the time needed for creating models by hand.
I encourage readers to consider using UT Libraries’ own digital collections (particularly the Middle East Studies Collection) as a source of digitized images of text if they want to give eScriptorium a try. UT Libraries also has worked closely with FromThePage, a transcription tool for collaborative transcription and translation projects. The crowdsourcing and collaborative options available with FTP will be useful to many projects focusing on documents too challenging for the capabilities of today’s OCR and HTR tools. Don’t forget to share your projects and let us know how these tools and materials have helped your research!
Dale J. Correa, PhD, MS/LIS is Middle Eastern Studies Librarian and History Coordinator for the UT Libraries.