

Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
Increasingly simple and cost-effective digital technologies have made capturing and distributing oral histories a robust and growing field for archivists and for researchers, and, by extension for students and scholars seeking primary source, personal narratives to augment their understandings of history. One of the most compelling South Asian oral history projects is the 1947 Partition Archive. The Archive’s mission is to preserve eyewitness accounts from those who lived through the exceptionally turbulent and violent period when the Indian subcontinent gained independence from Britain, divided into the nation-states of India and Pakistan, and millions of people migrated from India to Pakistan, from Pakistan to India, from India and Pakistan to other parts of the world. The work of the Archive is especially pressing: it has been 72 years since Partition and those still alive and able to directly recount their stories are increasingly rare. As such, the core of the Archive’s work is to use its digital platform to encourage and motivate more interviews.
Using the power of “the crowd” to create content as well as to fund itself, the 1947 Partition Archive is demonstrably transparent in its methodologies; of particular use to those new to video oral histories is their “Citizen Historian Training Packet” which walks a novice through best practices for interviewing, strategies for good video capture, recommendations for incorporating still images into videos and even how to employ social media to generate interest (and potentially more interviews!). The Archive has gathered over 5000 interviews so far and uses a very persuasive interactive map (StoryMap) on its front page to document the scale and scope of migration while simultaneously indexing the interviews; on the map itself, try searching a city either in “migrated to” or “migrated from” to generate a list of interviews, many with detailed text summaries that can be easily shared through social media, email, etc.
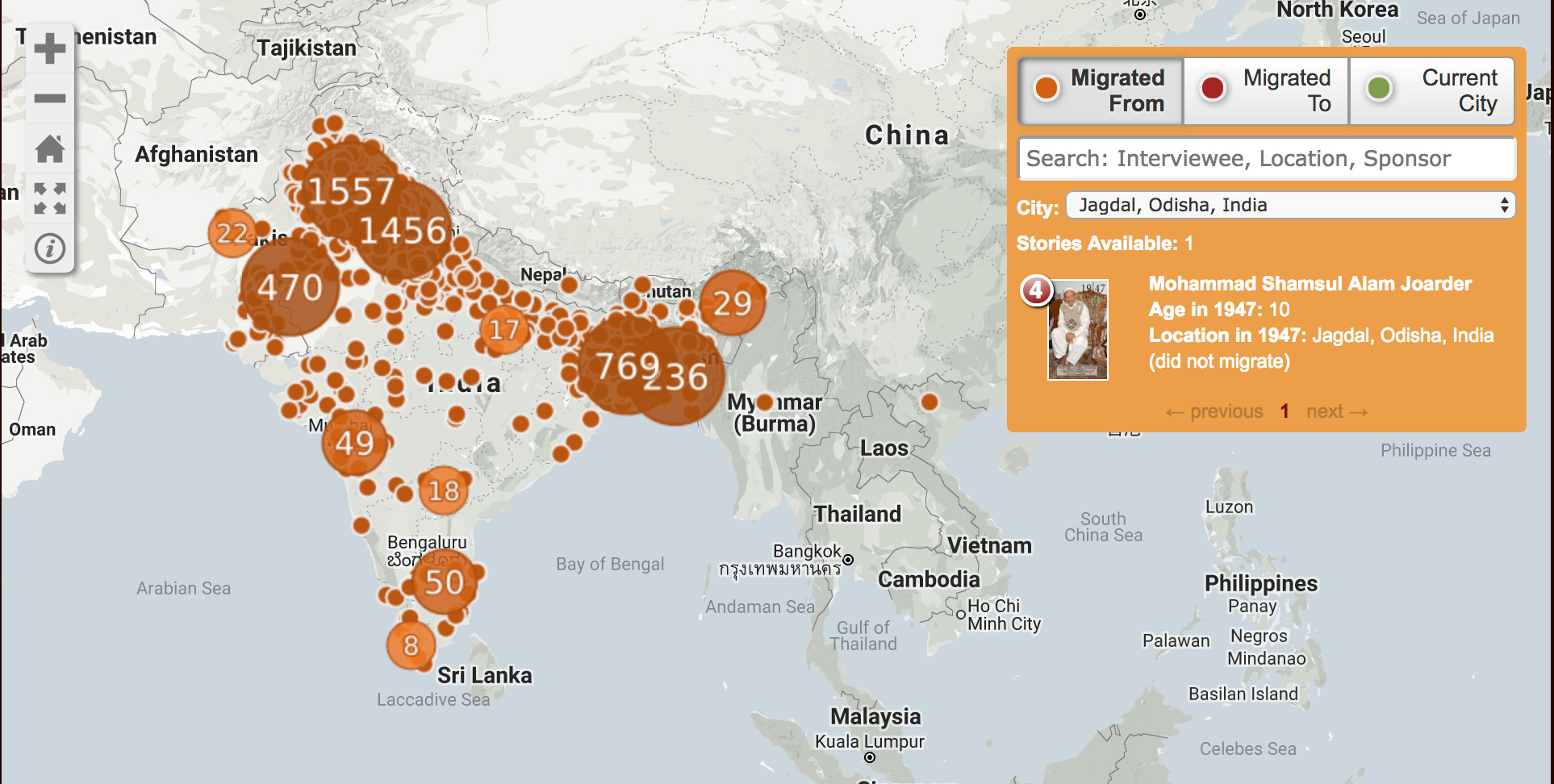
A handful of video interviews are available on the front page of the Archive’s website and raw, unedited recordings are available upon request.
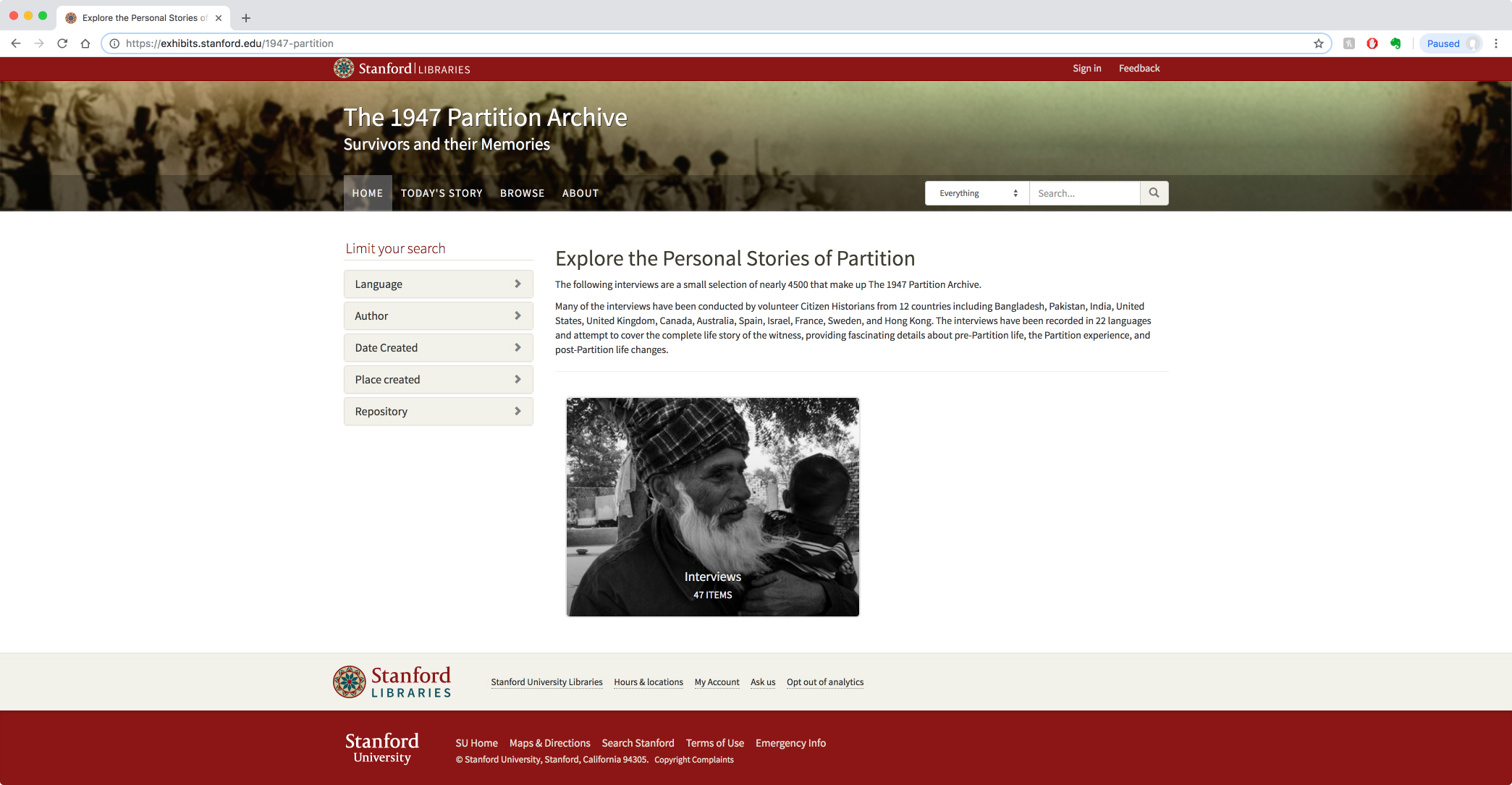
Recently the Archive has partnered with Stanford University Library to preserve and archive the recordings. To date, approximately 50 interviews are available through streaming on the site and (contingent on funding) one can hope for more to be available soon. On the Stanford site, one can navigate by language, author, place & date of recording, but those just beginning to explore the subject may find the “Today’s Story” a good place to start.
The stories bravely shared through the 1947 Partition Archive are simultaneously compelling and devastating in their intimate descriptions of destruction, of violence, of loss. And yet, they also provide hope: all interviewees survived the ruin that was Partition and the very act of sharing their stories demonstrates a hope for and generosity towards future generations to learn from the past.
The UT Libraries has an extensive collection related to Partition; those new to the topic might begin with a short story by Saadat Hasan Manto, “Toba Tek Singh,” a novel by Khushwant Singh, Train to Pakistan, or by Salman Rushdie, Midnight’s Children, or Vishwajyoti Ghosh’s curated graphic novel, This Side, That Side.




{kind=link}