

Read, hot & digitized: Librarians and the digital scholarship they love — In this new series, librarians from UTL’s Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of and future creative contributions to the growing fields of digital scholarship.
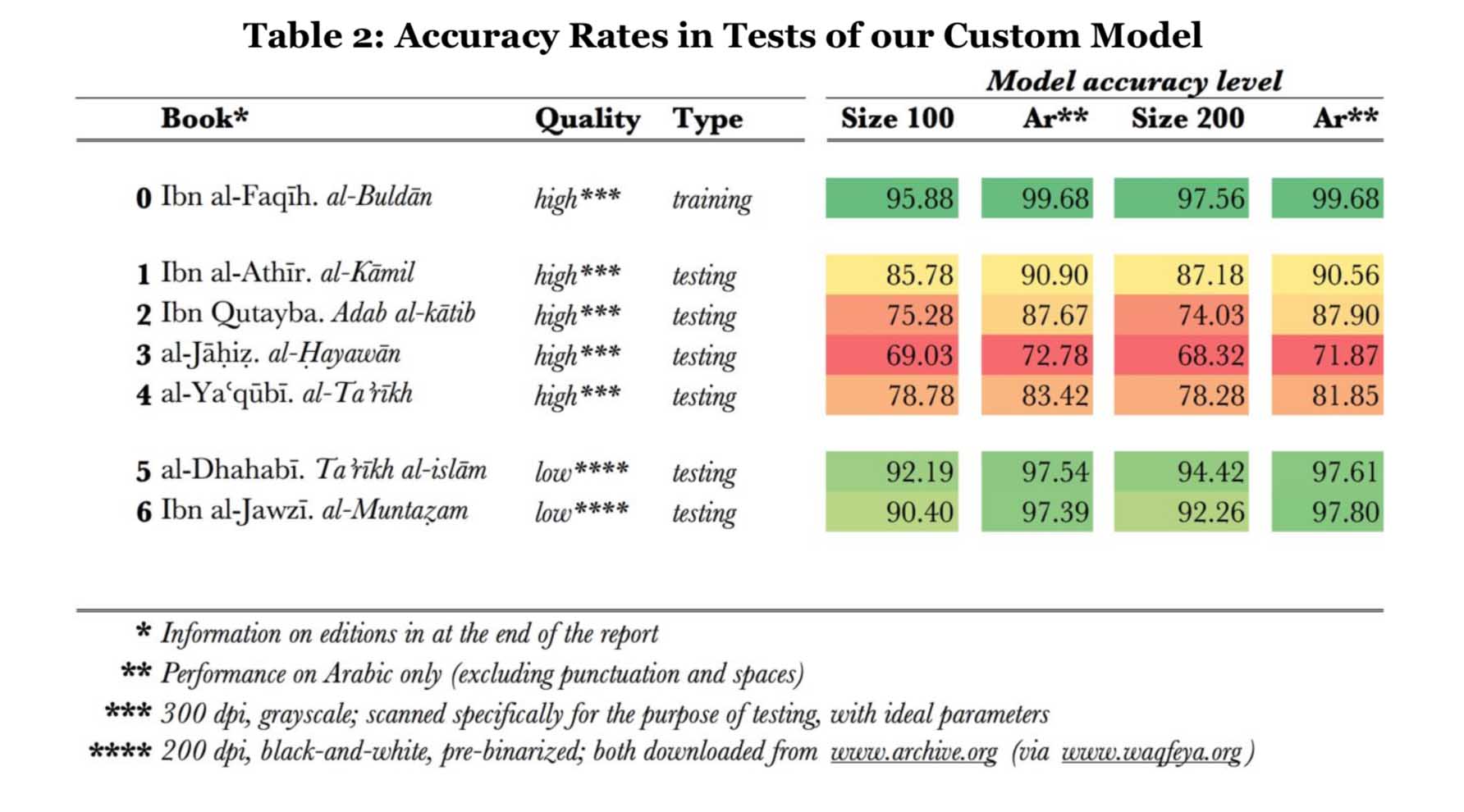
The KITAB Project, headed by Sarah Bowen Savant of the Aga Khan University, seeks to develop tools and techniques for producing scholarship on text reuse and intellectual networks in the premodern Arabic textual tradition. The project is based on a digital corpus of published texts that represent all genres of writing in Arabic from the earliest works to the beginning of the 20th century CE. Although the corpus draws in part from digital databases of texts, it also relies heavily on digital surrogates of printed volumes which require Optical Character Recognition (OCR) for computational analysis. The KITAB project has partnered with the Open Islamicate Text Initiative to develop an OCR software that has proven more successful than commercially-available products. The collaboration’s published results of this OCR development—called Kraken—can be found here.
The KITAB project is noteworthy not only for bringing the concepts of text reuse and distant reading to Middle Eastern Studies from a digital humanities perspective, but also for its development of tools designed for Arabic script languages. The needs of right-to-left and non-Roman script languages such as Arabic, Persian, Ottoman Turkish, and Hebrew—namely bidirectionality and non-Roman script recognition capabilities—unfortunately have been neglected to date in key tools utilized by highly successful digital humanities projects. The KITAB project brings the necessity of right-to-left and non-Roman capabilities to the fore by centering the Arabic textual tradition and committing to the development of tools that best meet the needs of the questions asked.
In addition to Dr. Savant, the team behind the KITAB project includes scholars from the U.S. and Europe, notably David Smith (Northeastern University) who developed the passim software upon which the text reuse project is based, and Maxim Romanov (University of Vienna) who heads the Open Islamicate Text Initiative. The team supports the continuing evolution of algorithms that seek to determine which Arabic texts were most quoted, most used by historians, and most commented on over several centuries (roughly 700-1500 CE). These questions might be answered simply enough within one text with a full-text search engine. However, to answer these questions across the Arabic textual tradition requires not only a massive corpus (currently over 4200 items), but also incredible computing power.
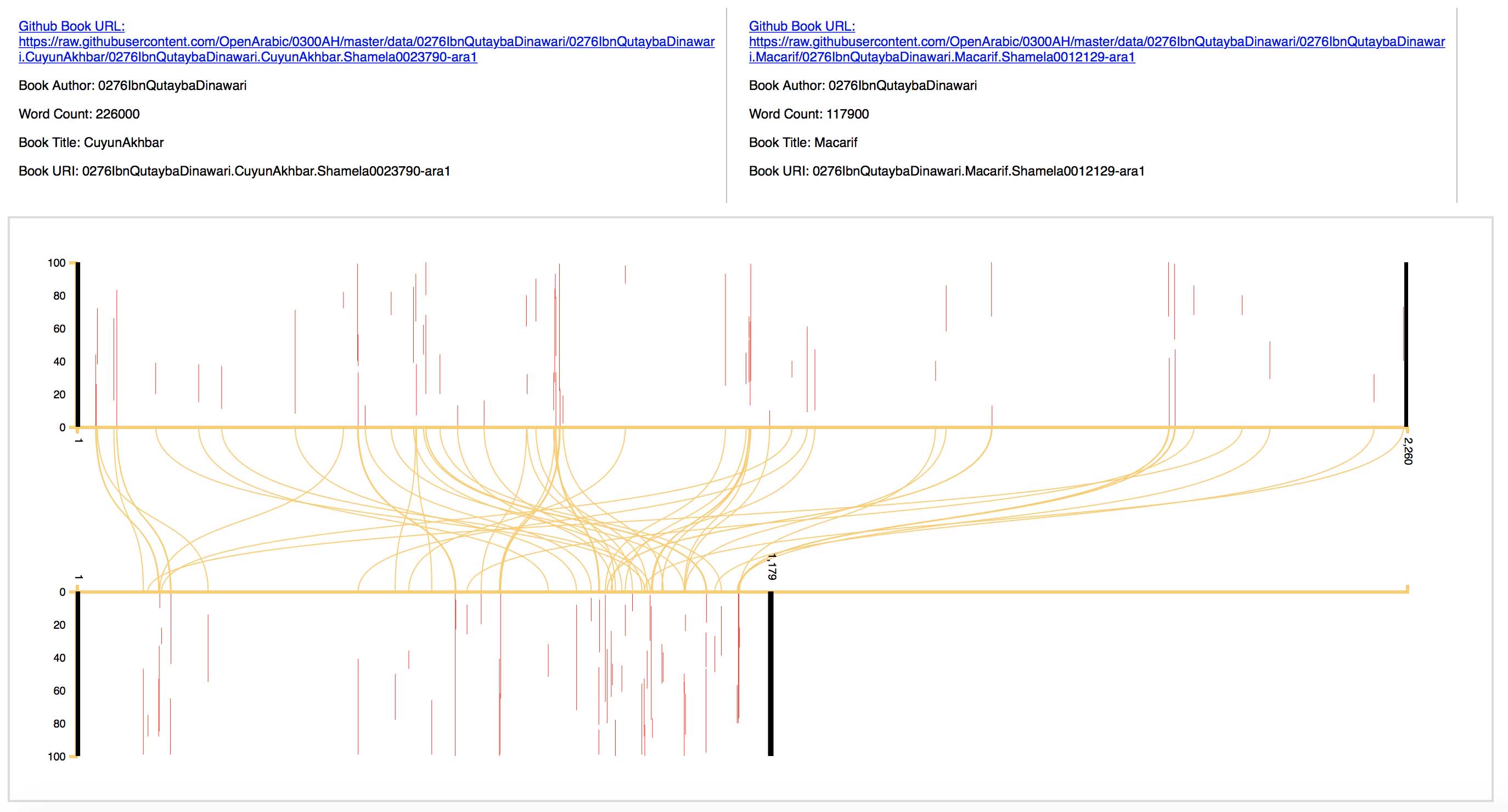
I encourage readers to take a look at the latest text reuse visualization from the corpus, which is based on two works by Ibn Qutayba (d. 889 CE). I also suggest reading Dr. Savant’s critically reflective post on running the passim software across the entirety of the corpus, and the questions raised by the results about intertextuality and what text reuse means in the Arabic context. Lastly, I recommend that those interested and/or involved in the field review information on the KITAB Project’s corpus, including the FAQ links to the Open Islamicate Text Initiative for suggesting new digital titles and new titles requiring OCR. UT Libraries’ collection of historic Arabic texts is one of the largest in the United States and ripe with suggestions for the KITAB corpus (check out this Islamic Empire — History subject heading search to see a sample of UT’s rich Arabic collections).