
In my role as European Studies Liaison, one of my priorities is to assist people in their digital humanities work. In that work, I have found a glaring gap in tools that support multilingual and non-English materials, particularly those that focus on natural language processing (NLP). Much of the work that has been done using NLP has been focused on an Anglocentric model, using English texts in conjunction with tools and computer models that are primarily designed to work with the English language. I wanted to make it easier for people to begin engaging with non-English materials within the context of their NLP and digital humanities work, so I created Rozha.
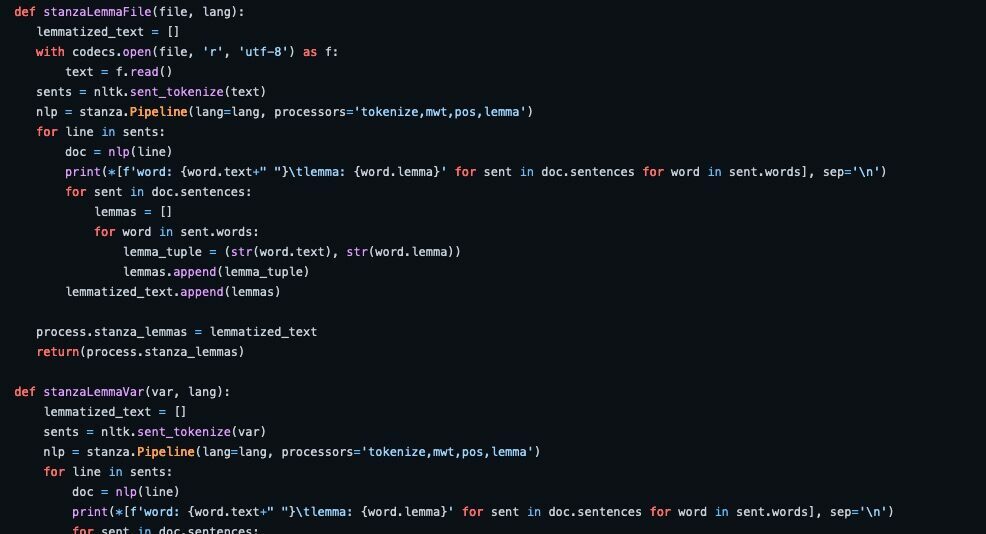
Rozha, a Python package designed to simplify multilingual natural language processing (NLP) processes and pipelines, was recently released on GitHub and PyPI under the GNU General Public License, allowing users to use and contribute to the tool with minimal limitations. The package includes functions to perform a wide variety of NLP processes using over 70 languages, from stopword removal to sentiment analysis and many more, in addition to visualizations of the analyzed texts. It also allows users to choose from NLTK, spaCy, and Stanza for many of the processes it can perform, allowing for easy comparison of the output from each library. Examples of the code being used can be seen here.
While the project first grew out of the needs of researchers and graduate students working at UT-Austin who were interested in exploring NLP and the digital humanities using non-English languages but who did not have very much prior coding experience, its code also aims to streamline NLP work for those with more technical knowledge by simplifying and shortening the amount of code they need to write to accomplish tasks. Output from the package’s functions can be integrated into more complex and nuanced workflows, allowing users to use the tool to perform standard tasks like word tokenization and then use the response for their other work.
The package is written in Python for a variety of reasons. Python has a wide base of users that makes it easy to share with others, and which helps ensure that it will be used widely. It also helps ensure that people will contribute to the project, building upon its existing code. Fostering contributions for multilingual digital humanities and NLP can help broaden the community of scholars, coders and researchers working with these multilingual materials, which will broaden the community in general while also improving the package. Python is also very commonly used for NLP applications, and the packages integrated into Rozha all have robust communities of their own. This allows for users to connect with other communities as well, and to explore these technologies on their own for applications beyond what this package provides.
The Rozha package ultimately aims to make multilingual digital humanities and natural language processing more accessible and to simplify the work of those already working in the field–and perhaps open up new avenues to explore for newcomers and established NLP practitioners. My hope is that this tool will help encourage diversity in the NLP landscape, and that people who may have felt it too daunting to work with materials in non-English languages may now feel more comfortable through the ease of working with this package. Beyond that, I hope the package will serve as a conduit for additional contributions and collaboration, and that the code will ultimately help strengthen the field and community of practitioners working with non-English materials.