
Read, hot & digitized: Librarians and the digital scholarship they love — In this series, librarians from the UT Libraries Arts, Humanities and Global Studies Engagement Team briefly present, explore and critique existing examples of digital scholarship. Our hope is that these monthly reviews will inspire critical reflection of, and future creative contributions to, the growing fields of digital scholarship.
While digital, machine-readable texts in Arabic are growing in their availability, certain genres of writing and scholarship in Arabic have become more readily accessible than others. Among those more obscure disciplines are Sufism, theology (Muslim and Christian), and philosophy. These tend to be theoretically complex, and even dogmatically challenging, disciplines that are not as well represented in North American Islamic Studies programs as literature or Qur’anic studies. The Nuṣūṣ corpus––a project led by Antonio Musto––seeks to fill in some of the desiderata by putting more texts from these essential disciplines up on the Internet for researchers to use.
A project that began with an almost exclusive focus on Sufism, Nuṣūṣ has expanded to include works from a variety of complex disciplines of Arabic-language scholarship produced by Muslims and Christians. The corpus currently contains 61 machine-readable texts, with plans to add more and to make the text files available for download. Differing from other, larger corpora of Islamicate[1] disciplines, Nuṣūṣ provides the bibliographic information for the modern editions from which these digitized texts are derived. This is not only a responsible move, but a useful one for researchers: modern editions of historic texts can differ greatly; comparing modern editors’ approaches to the text and their choices that affect meaning and understanding is therefore rich area of exploration in Arabic-language digital humanities. It is hoped that––as possible––Nuṣūṣ will start to add multiple editions of historic texts in order to facilitate this comparative work.
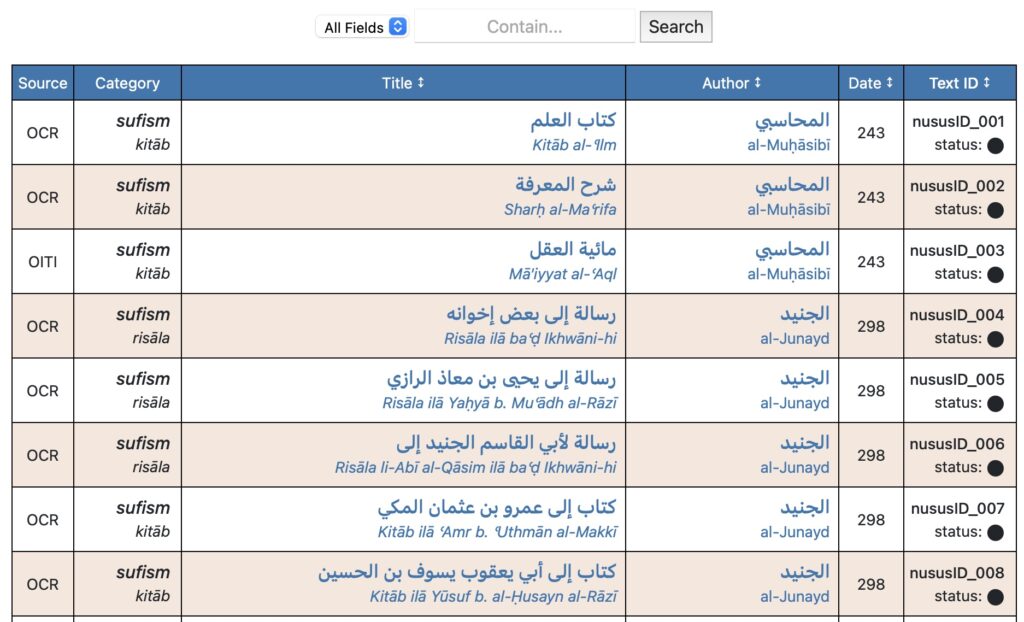
Nuṣūṣ’s aspirations lie in providing researchers with an adequate corpus from which to do computational text analysis. To that end, the team has created several different ways for researchers to access and engage with the texts. The “Browse Corpus” feature gives researchers an accurate sense of which specific items are included. If one is looking for a particular author or text, this would be the list to consult. This is also where crucial metadata (information about the item) is located, such as the origin of the digital images (Nuṣūṣ’s own OCR process or the OpenITI project repository), the internal corpus text ID, the date of the historic text’s alleged composition, the discipline, the genre of writing, the title, and the author. Author names link to biographies from the Encyclopaedia of Islam, and titles link to the WorldCat record for the modern edition used in the digitization of the text.
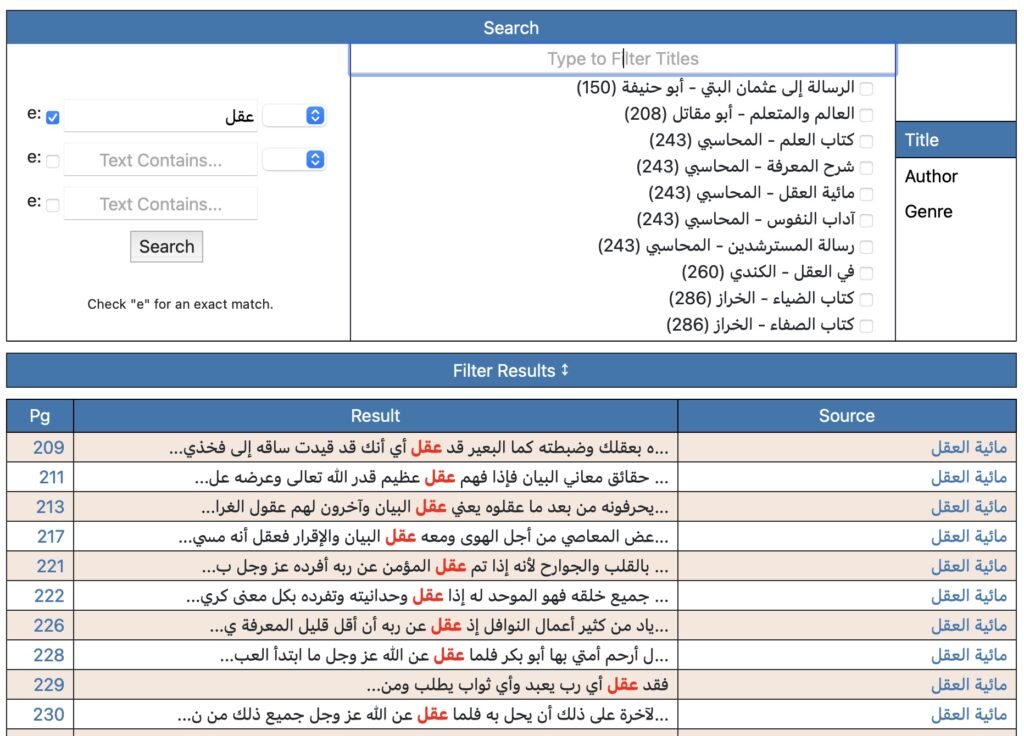
Furthermore, the Nuṣūṣ team has provided a cross-corpus search tool. Researchers can build a search using the provided fields and Boolean operators (AND, OR), and can specify whether they are searching for an exact term. It is also possible to confine the search to specific titles, authors, or genres. This arrangement encourages researchers to pursue projects that might compare across a scholar’s oeuvre, across a genre of writing (Muslim theology, philosophy, Sufism, or Christian theology), or across a single text. Researchers could use this tool to construct searches across known networks of scholars, as well. As the corpus expands, the ability to conduct searches and collect the resulting data will become increasingly effective and useful.
Readers interested in text and corpora analysis should consult the UT Libraries’ Digital Humanities Tools and Resources guide for more information on methods to apply to corpora like Nuṣūṣ. For recommendations of other corpora that might be useful for your research, consult the Data Set list on the Text Analysis guide. Lastly, as the Nuṣūṣ corpus partners with and derives from the OpenITI repository, it is worth considering the OpenITI repository documentation at the KITAB project. Happy corpus hunting!
Dale J. Correa, PhD, MS/LIS is Middle Eastern Studies Librarian and History Coordinator for the UT Libraries.
[1] The term Islamicate was coined by Marshall G.S. Hodgson in volume 1 of his The Venture of Islam (p. 57).