Most people think of SXSW as a giant party. But a for a group of us from the UT Libraries this year, SXSW presented an opportunity to make Wikipedia a more welcoming and representative place for LGBTQ+-identified people.
It started with an idea from some great folks at WNYC Studios, a public radio station in New York, to host an LGBTQ+ Wikipedia Edit-A-Thon during SXSW. WNYC produces the acclaimed podcast Nancy that covers modern queer identity. Hosts Kathy Tu and Tobin Low were at the festival to present on diversity in podcasting and wanted to do more in their off-time while in Austin. They noticed that many queer and trans topics don’t have robust Wikipedia pages, if they had pages at all, so they decided to tackle these significant information gaps.
I linked up with them in January, when they had the wisdom to reach out to librarians in Austin to assist with this event, Keep Wikipedia Queer. Event planning is more than one-person job, and I was able to partner with some graduate students from iSchool Pride, a group from the School of Information.
As we began planning, we realized that many people from UT might not be in town during SXSW. To encourage as much UT participation as possible, we decided to host Queering the Record, a pre edit-a-thon research event at the PCL during the week before Spring Break. Queering the Record provided structured time, space, and snacks for librarians, students, faculty, and staff to use library resources to identify topics that need Wikipedia pages and collect a list of sources that could be used and cited by edit-a-thon participants. More than 35 people attended Queering the Record, and by the end, we created a 23-page Google doc that we were able to share and work from at Nancy’s Edit-A-Thon.
Speaking of Nancy’s event – it was a lot of fun! During the 4-hour event held downtown, we met people from around Austin and around the country, all of whom are passionate about LGBTQ+ representation. Seven folks from UT attended, including some PCL Graduate Research Assistants, and we connected with a librarian from the City University of New York system. As a group, we edited more than 70 Wikipedia pages on topics as wide-ranging as comedian/blogger Samantha Irby, LGBTQ+ rights in Syria, Austin’s QueerBomb celebration, and the children’s book series Frog and Toad.
The response to both of these events from students and staff was so positive that we hope to hold more LGBTQ+ Wikipedia edit-a-thons in the future!
A group photo from the SXSW event Keep Wikipedia Queer, including librarians and student staff from the UT Libraries. Photo by Jeanette D. Moses/WYNC
Special thanks to iSchool student and PCL GRA Elle Covington for her contributions to these events!
March 5-9 is Open Education Week Throughout the week, guest contributors will present their perspectives on the value of open education to research, teaching and learning at The University of Texas at Austin. Today’s installment is provided byJeannette Okur, Lecturer, Middle Eastern Studies.
Jeannette Okur
For a year and a half now, I have been designing and piloting an OER textbook and online curricular materials designed to bring adult learners of modern Turkish from the Intermediate-Mid/High to the Advanced Mid proficiency level. The textbook, titled Her Şey Bir Merhaba İle Başlar (Everything Begins With A Hello), will – hopefully – be available on the UT Center for Open Education Resources and Language Learning (COERLL) website in Fall 2019; and the complementary series of primarily auto-correct listening, viewing, reading and grammar exercises and quizzes will be made available on a public Canvas course site. This new set of OER materials is aligned with the ACTFL standards for Intermediate- and Advanced-level communicative skills and intercultural proficiency descriptors, and also reflects my department’s (and my personal) commitment to blended instruction and the flipped classroom model. I’ve now designed five thematic units that promote the following pedagogical goals:
Introduce the learner to culturally and socially significant phenomena in Turkey today.
Introduce the learner to various print, audio and audio-visual text types aimed at native Turkish audiences and guide them to use (and reflect on) the reading, listening and viewing comprehension strategies needed to understand these Advanced-level texts.
Engage the learner in active recognition and repeated practice of new vocabulary and grammar items.
Guide the learner through practice of oral and written discursive strategies specific to the Advanced proficiency level.
Balance the four communicative skills.
Balance seriousness and fun!
I’m excited about OER’s potential to transform students’ and teachers’ experiences with Less Commonly Taught Languages (LCTL) like Turkish. A readily accessible and modifiable OER for this level of Turkish language instruction, in particular, makes a whole lot of sense, because the for-profit textbook model is a non-starter! In other words, because no one can make a profit off of Turkish language teaching materials outside of Turkey; few of the teaching materials that U.S.-based Turkish language instructors design ever get published or shared. In fact, creating an OER for Turkish-language learning has made sharing my ideas, teaching materials and methodology possible!
I believe wholeheartedly that being able to share and modify OER teaching/learning materials via online platforms leads to collaboration among educators and eventually to better educational products and practices. I hope that other Turkish language educators, upon engaging with my OER materials, will learn a few small but important lessons from me, namely:
Adults learning Turkish need help practicing and learning vocabulary, not just grammar.
Identifying and discussing cultural differences/commonalities on the basis of actual socio-cultural phenomena captured in texts aimed at target culture audiences is key to increasing learners’ cultural proficiency, especially when those learners are not learning in the target culture.
The blended instruction/flipped classroom model really works because engagement with reading, listening and grammar materials at home gives learners more time to practice SPEAKING in class (or with a tutor).
I also look forward to learning from the colleagues and learners who engage with my materials in varied settings beyond the University of Texas at Austin.
March 5-9 is Open Education Week Throughout the week, guest contributors will present their perspectives on the value of open education to research, teaching and learning at The University of Texas at Austin. Today’s installment is provided by Jocelly Meiners, Lecturer, Department of Spanish and Portuguese.
Jocelly Meiners
In recent years, the development of Spanish language courses designed specifically for heritage language learners has gained much attention throughout K-12 and post-secondary education in the US. Heritage language learners are students who were exposed to Spanish at home while growing up. These students usually have a broad knowledge about their cultural heritage, and varying degrees of language dominance. Over the years, it has been found that these learners have different pedagogical needs than second language learners, and that they benefit greatly from language instruction that is catered to their specific needs. Throughout the country, as more institutions realize these needs, Spanish instructors at all levels are forming programs and creating materials to serve this student population. It seems that we all have some common goals: to help heritage Spanish speakers develop their bilingual skills, to empower them to apply those skills in academic and professional settings, and to feel proud of their cultural and linguistic heritage. So if we all have similar goals in mind and are all working on creating programs and materials to serve these students, why not share all the work we are doing?
I have been teaching courses for heritage Spanish learners here at UT for over 4 years, and about a year and a half ago I started working as the community moderator for the Heritage Spanish Community (https://heritagespanish.coerll.utexas.edu). This web-based community, which is hosted by COERLL (The Center for Open Educational Resources and Language Learning), serves as a space for Spanish instructors to collaborate, share and communicate with others about the teaching and learning of Spanish as a heritage language. We encourage instructors at all levels to ask questions on our online forum, to help other instructors, and to share the materials they are working on. Open Educational Resources are an excellent way to share these types of materials, since they can easily be adapted to the specific needs of each instructor’s particular student population.
As community moderator, I add useful content to our website, create interesting questions for discussion, and encourage others to explore our website and share their work. I have also been able to share my own materials as OER, and it has been very rewarding to hear form people in other parts of the country who have found my resources useful and are adapting them for their own heritage Spanish programs. I believe that if we all collaborate and share our resources openly, we will be much more successful in attaining both our personal and common goals.
March 5-9 is Open Education Week Throughout the week, guest contributors will present their perspectives on the value of open education to research, teaching and learning at The University of Texas at Austin. Today’s installment is provided by Orlando R. Kelm, Associate Professor, Department of Spanish and Portuguese
Orlando R. Kelm
Open Access seems to be at the core of materials development for those of us who teach what is called LCTLs (less-commonly taught languages). In academic settings, publishing companies are less likely to take a chance on publishing materials where the market is small. There have been multiple occasions when I have been told by publishing companies something similar to, “If you could do this project for us in Spanish we would be interested, but unfortunately the market in Portuguese is not big enough to take on such a project.” Although it has been discouraging to hear such replies, it was also understandable.
However, it today’s world of innovative technologies, online, electronic, digital, social media, video and podcasts, Open Access pedagogical materials in foreign language, especially for the less-commonly taught languages, have provided a boon of opportunities. Here at the University of Texas at Austin, for example, the College of Liberal Arts (LAITS), the Center for Open Educational Resources and Language Learning (COERLL) and the Center for Global Business have all been supportive of our development of online and open access materials for those who want to learn Portuguese. COERLL helps maintain our BrazilPod site, where all our Portuguese materials are available for everyone, anytime, Open Access, and with Creative Commons license. Here’s the URL: https://coerll.utexas.edu/brazilpod/index.php
This site contains a number of videos, podcasts, exercises, transcripts, translations, and a number of other materials. We have seen how users, both teachers and private learners, have integrated, modified and added these materials to the study of Portuguese. Some access the materials online, others embed content into exercises and quizzes, others create ancillary activities for organized courses. Open Access has revolutionized the way that learners of LCTLs share materials and expose learners to content.
It also seems a bit ironic when we think of the initial rejection from publishing companies. If they were to approach us today to publish in traditional formats, chances are that we would react by saying, “Thanks, but our ability to share with Open Access works for us better than the traditional publication methods.”
October is Open Access Month. Throughout the month, guest contributors will present their perspectives on the value of open access to research, scholarship and innovation at The University of Texas at Austin.
This installment provided by Rayna Harris (ORCID ID:0000-0002-7943-5650), PhD Candidate, Cell and Molecular Biology.
Open access publishing is critical for ‘daisy chain’ reading of scientific papers
Rayna Harris.
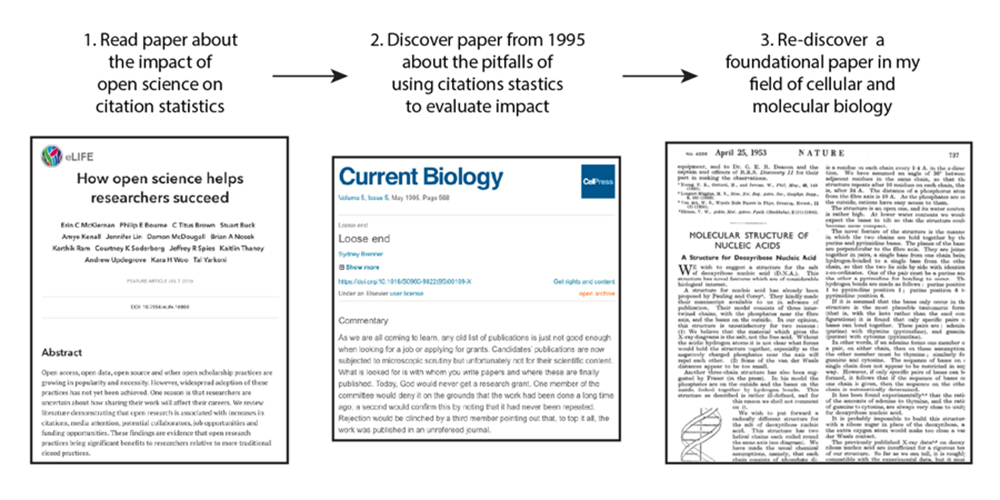
Whenever I read a scientific paper, there is almost always a citation that grabs my attention and begs to be read. I love it when I can click on a citation and then read the full text. This ‘daisy chain’ process of citation searching (where the second paper leads me to a third paper, which leads me to a forth, and so on) gives me a great appreciation for all the previous research that contributes to current knowledge.
Figure 1. An example of citation searching or ‘daisy chain’ reading of scientific papers. In this example, McKiernan et al. 2016, cite Brenner 1995, who refers to Watson & Crick 1995. All these papers are open access and can be read by all.
When my citation search leads me to a paper that is not open access, I get frustrated because its halts the excellent momentum I had going for gaining new new knowledge. There is a saying in my lab that “if the research isn’t published it doesn’t exist” because it has not been disseminated to broader audiences. I would like to modify this quote to say “if the research is not published and open access then it doesn’t exist” because pay-walled papers are not freely discoverable.
Open access publishing is necessary for dissemination of ideas because it gives readers the ability to read any paper anytime anywhere. My hope is that one day I will publish a scientific paper that 1) is open access, 2) cites only open access papers, 3) which in turn cite only open science papers, and so on. This way, future readers can daisy-chain their way through the history of research that lead to current understanding.
As we prepared for Open Access (OA) Week 2017, it’s been exciting to think back about how far we’ve come in the last several years. For those who aren’t familiar, OA Week is a celebration of efforts to make research publications and data more accessible and usable. Just ten short years ago we lacked much of the infrastructure and support for open access that exist today.
By 2007 we had implemented one of the core pieces of our OA infrastructure by joining Texas Digital Library (TDL). TDL is a consortium of higher education institutions in the state of Texas. TDL was formed to help build institutions’ capacity for providing access to their unique digital collections. That membership continues to grow and TDL now hosts our institutional repository, Texas ScholarWorks, our data repository, Texas Data Repository, our electronic thesis and dissertation submission system, Vireo, and is involved in our digital object identifier (DOI) minting service that makes citing articles and data easier and more reliable. These services form the backbone of our open access publishing offerings.
Our institutional repository, Texas ScholarWorks (TSW), went live in 2008. TSW is an online archive that allows us to share some of the exciting research being created at the university. We showcase electronic theses and dissertations, journal articles, conference papers, technical reports and white papers, undergraduate honors theses, class and event lectures, and many other types of UT Austin authored content.
TSW has over 53,000 items that have been downloaded over 19 million times in the past nine years.
In spring of 2017 we launched the Texas Data Repository (TDR) as a resource for those who are required to share their research data. TDR was intended to serve as the data repository of choice for those researchers who lack a discipline-specific repository or who would prefer to use an institutionally supported repository. TDR serves as a complementary repository to Texas ScholarWorks. Researchers who use both repositories will be able to share both their data and associated publications and can provide links between the two research outputs.
For several years the library has been supporting alternative forms of publishing like open access publishers and community supported publishing and sharing. Examples of this support include arXiv, Luminos, PeerJ, Open Library of the Humanities, Knowledge Unlatched, and Reveal Digital. These memberships are important because it’s a way for us to financially support publishing options that are more financially sustainable than the traditional toll access journals. Many of these memberships also provide a direct financial benefit to our university community, like the 15% discount on article processing charges from our BioMed Central membership.
In an effort to lead by example, the UT Libraries passed an open access policy for library staff in 2016. This is an opt-out policy that applies to journal articles and conference papers authored by UT Libraries employees. With this policy the library joins dozens of other institutions across the U.S. that have department level open access policies.
This past year we started a very popular drop-in workshop series called Data & Donuts. Data & Donuts happens at the same time every week, with a different data-related topic highlighted each week. All the sessions have a shared goal of improving the reproducibility of science.
Data & Donuts has attracted over 340 people in the past nine months which makes it one of our most successful outreach activities.
We have another reason to be optimistic this year. The Texas state legislature passed a bill this summer that should expand the awareness of and use of open educational resources (OER). SB810 directs colleges to make information about course materials available to students via the course catalog. If there is an online search feature for the catalog, the college has to make it possible for people to sort their search by courses that incorporate OER. The catalog functionality is set to go into effect this spring, so we’ll be keeping an eye on how things develop over this academic year.
We will continue the momentum we have generated from the launch of TDR, our Data & Donuts series, and our support of open publishers. We are putting together topics for Data & Donuts this spring, planning events associated with open access and author rights, and continuing to improve our online self-help resources. We are committed to offer assistance to any faculty, staff, or student at the university who has a question about open access.
We encourage department chairs and tenure and promotion committees to talk with their colleagues and/or engage with us in discussions about what open access means for their discipline.
UT Libraries will continue to explore new publishing models and initiatives to share UT’s rich scholarship and discoveries, to find ways to increase access to open educational resources, and to support future faculty and scholars in accessing, using and curating the growing body of data that is central to the research enterprise.
October is Open Access Month. Throughout the month, guest contributors will present their perspectives on the value of open access to research, scholarship and innovation at The University of Texas at Austin.
This installment provided by Dr. Maryjka B. Blaszczyk,Postdoctoral Research Associate, Department of Anthropology.
A need for open access to research materials to spur new discoveries in biological anthropology
Dr. Maryjka B. Blaszczyk.
A major aim of research in biological anthropology is to understand how humans have ended up looking and behaving the way that they do. To understand the evolution of our body form, anthropologists look at fossils. Behavior, however, does not fossilize, and so we turn to studying our closest living relatives, the nonhuman primates, preferably in their natural habitats where they have to deal with selective pressures such as avoiding predators and finding enough food to eat. Primate behavior field data are hard-won, involving substantial investments of time and resources. Apart from jumping through logistical hoops such as obtaining permits and building relationships with local stakeholders in far-flung locales, establishing a new field site for behavioral fieldwork involves months if not years of patiently following wild primates around to habituate them to researchers’ presence. Once habituated, data collection begins, with blood, sweat, and tears invariably spilt as one accumulates precious hours of detailed behavioral observations on this group of primates at this place and particular time.
These investments are one reason given by field primatologists as justification for closely guarding their data. Another is the unique insights they have into the lives of their study animals, having spent hours upon hours of observation time with them. Some primatologists argue that researchers not familiar with their study site and animals may misuse the data if they were to make it widely available, subjecting it to improper analyses or not accounting for information about the study site/animals that is known only to researchers who have worked there. Researchers also generally have many ideas for secondary analyses of their data that they plan to get to in the future.
Each of these arguments is by no means specific to primate behavioral ecology, with very similar arguments having been made, for example, by medical researchers working with clinical trial data. Of course, clinical trial data has a substantially higher status (given its applications for human health and welfare) than primate behavior data, and arguments about the costs and benefits of trial data sharing have been ongoing in high profile forums for several years. Data sharing advocates point to benefits such as new discoveries, better metanalyses, and correction or confirmation of findings in the scientific record, which they argue far outweigh potential risks such as incorrect analyses or data misuse. We all know researchers who have been sitting on data for years (even decades) with plans for secondary analyses, many of which they will never find the time to conduct and publish. In the case of primate field data collected on a specific population at a specific place and point in time – and frequently on endangered primates living in rapidly changing habitats – these data cannot be reproduced, so it is a double shame that they may never make it into the scientific record.
Primate behavioral ecologists are included in Anthropology departments because comparative studies on primate behavior illuminate the ways in which humans differ from and are similar to our closest kin, allowing us to better understand the evolutionary ecology of our lineage. However, many comparative studies are hampered by poor descriptions of how data in primate field studies were collected and processed, and many large-scale comparative studies cannot be undertaken unless raw data itself is made available. Behavioral ecologists should take a page out of their molecular primatology colleagues’ playbooks, where publication of genetic data alongside scientific articles is the rule. This type of data sharing has enabled large-scale comparative phylogenetic studies that have given us a rich understanding of primate evolution. It is time for primate behavioral ecologists to catch up and to make sharing of data as well as associated behavioral and ecological data collection protocols the norm. Who knows what insights await us.
October is Open Access Month. Throughout the month, guest contributors will present their perspectives on the value of open access to research, scholarship and innovation at The University of Texas at Austin.
This installment provided by Spencer J. Fox (ORCID ID: 0000-0003-1969-3778), PhD candidate focusing on computational epidemiology.
Spencer J. Fox.
Three years ago, I was choosing the next research direction for my PhD. I was interested in two subjects and had found a journal article in each to build upon. I thought to follow the computational biologist’s path of least resistance: pursue the paper whose results I could reproduce first, as that represents an important first step. One of the papers had published a repository with all of their data alongside working code for analyzing it, while the other had simply stated: “Data available upon request” with no reference to code used for the analyses.
Being a naive graduate student, I politely reached out to the authors of the second study to obtain their data and inquire about their code. In return, I received a scathing email filled with broken links to old websites, excuses about proprietary data, and admonishment for having asked for “their” code: “any competent researcher in the field could replicate our analysis from the information within the manuscript.” I was stunned.
While expressing my frustration to my peers, I found that their requests had also been met with equal hostility and degradation from scientists in their respective fields. When data or code had been provided – usually after months of negotiations – cooperation came with heavy stipulations in article authorship, time-stamped embargos, or permissible analyses. Clearly, it’s not enough to rely on researchers to act in good faith.
The unfortunate truth is that the onus falls on journals to enact real change. Many major journals now require that raw data be deposited in permanent online repositories like Dryad1. This has improved data sharing, but is only half the battle and simply provides the likeness of reproducible research. I have spent weeks reproducing someone’s analysis using their provided data and code. It would have been impossible without both. Simply put, freely available code – even if messy and difficult to follow – provides an invaluable foundation for future researchers to build upon, and all journals should require that both analysis code and data accompany a manuscript.
Too many conscious and subconscious coding decisions are made over the course of a project that even minor decisions early on present serious stumbling blocks for researchers trying to reproduce results. Differences in mundane behaviors between programming languages, versions, library functions, and self-written pipelines can have drastic implications on end results. A great example of this is the inadvertent errors in one fifth of genomics papers attributed to Microsoft Excel use2.
Finally, while ultimately it is the researcher’s responsibility to provide code alongside a manuscript, there are tangible incentives for doing so: citations. Open access manuscripts and those that provide their data receive more citations3,4, and the same likely applies to providing analysis code. After debating between those articles three years ago, I alone have cited the reproducible paper in two separate publications. How many other potential citations are lost “upon request”?
October is Open Access Month. Throughout the month, guest contributors will present their perspectives on the value of open access to research, scholarship and innovation at The University of Texas at Austin.
This installment provided by Sata Sathasivan, Senior Lecturer, Biology Instructional Office.
K.Sata Sathasivan.
I have been using open educational resources (OER) in biology as supplemental instructional sources for many years. These included animations, videos, simulations and public databases of DNA and protein. These resources are constantly evolving and they complement well with any level of teaching.
Recently, I started using a biology textbook published by Open Stax based at Rice University for my introductory biology classes successfully. While a publisher’s popular textbook may cost the students up to $250 each semester, OpenStax textbooks are free to download a PDF and have a nominal cost ($40) for printed versions. Several students liked this free textbook and I received only a few complaints about the inadequacies of this textbook to explain a particular concept. Overall, it was well received by the students and they found this very helpful.
This free textbook can be supplemented with other open educational resources that can be found online in various sites such as https://www.oercommons.org, and if you want to explore more OER sites, check this site.
The only concern that I have about OERs is the time it takes to check them for quality and consistency with your teaching, and the time involved in making the structure for them to be seamlessly integrated into the course.
Sunny June weather welcomed a lively group of 126 faculty, graduate students, and information professionals to the University of Texas Austin campus for HILT – Humanities Intensive Learning + Teaching. HILT is an annual week-long Digital Humanities (DH) training institute for researchers, students, early career scholars, and cultural heritage professionals. “HILT is awesome! It’s like nerdy summer camp for adults, and you actually learn things that are useful for your professional life,” one HILT participant in the course Introduction to the Text Encoding Initiative (TEI) for Historical Documentsstates.
In its 5th edition, HILT 2017 offeredeight immersive Digital Humanities training courses on tools and methodologies including Scalar, Python, text analysis, Text Encoding Initiative (TEI), audio machine learning, and crowdsourcing. Courses were led by 11 expert guest instructors, hailing from institutions across the United States, such as University of Delaware, Emory University and the University of Southern California Libraries. Participants each enrolled in one course of their choice and dove in for four intensive days of learning. The PCL Learning Commons and the College of Liberal Arts’ Glickman Conference Center served as classroom space.
Course group working.
“I really like the format of an intensive class,” a participant in HILT’s Text Analysis course reported. “It is different than other conferences I’ve attended where you go to hour-long sessions and someone presents on a project they did. I also found the instructors and participants to be extremely knowledgeable.”
UT Libraries staff partnered with School of Information and Department of English faculty to plan the 2017 institute in collaboration with HILT Co-Directors, Trevor Muñoz and Jennifer Guiliano. Combined with the expert DH knowledge of the course instructors, the team successfully executed the largest HILT institute yet, and participants shared an enthusiastic response.
“[The Black Publics in Humanities: Critical and Collaborative DH Projects] course has been one of the most enriching experiences of my professional life. Grateful for the work of these folks,” says HILT participant Casey Miles (Assistant Professor in the Writing, Rhetoric & American Cultures department at Michigan State University).
“HILT helped me learn real skills, make real connections, and plant seeds for a new path in research and teaching,” said one attendee. “It was the most valuable professional development work I’ve done since I filed my dissertation a decade ago, hands down.”
Keynote by Maurie McInnis.
Daily coursework was balanced with additional learning opportunities. Day one of HILT was activated by a keynote address from UT Austin Provost Maurie McInnis. Provost McInnis shared insights on the importance of digital humanities work through her own research experience. Mid-week, HILT participants shared their research insights with each other through lively 5-minute Ignite Talks. To facilitate networking platforms for this diverse group of participants, UT Libraries staff organized evening dine arounds at favorite local restaurants, and the UT Libraries and the Dolph Briscoe Center hosted social receptions. Participants were also invited to engage in UT Austin’s Cultural Campus through organized activities, including sunset viewing of James Turrell’s The Color Inside: A Skyspace, and specialized tours at the Blanton Museum of Art, Harry Ransom Center, and LBJ Presidential Library.
Attendees at James Turrell’s “Skyspace.”HILT sharing with Dale Correa.
UT Libraries was pleased to sponsor nine staff to attend HILT. Following the institute, a summer series, coordinated by the UT Libraries Digital Scholarship department, provided a venue for staff participants to share insightful overviews of what they learned in their courses.
One summer series session featured UT Libraries staff Beth Dodd, Christina Bleyer, and Susan Kung presenting on their Collaboration for Complex Research: Crowdsourcing in the Humanities HILT course experience. New insights will be applied to projects such as “Digitizing and Crowdsourcing the oversize Garcia Metadata” in the Benson Special Collections. Another session featured Dale Correa, who described TEI challenges with non-English, non-Roman languages as discussed in the Introduction to the Text Encoding Initiative (TEI) for Historical Documents course. The well-attended summer series informed a broader understanding of DH techniques among Libraries staff, fueled momentum for HILT-inspired projects, and generated a desire for additional training.
“I learned so much, especially to not be afraid of learning. It was phenomenal. I can’t imagine not returning every year for new courses,” shared a participant in the HILT course Getting Started with Data, Tools and Platforms.
Among all 2017 HILT participants, 98% say they will recommend HILT to a friend or colleague. With new and similar courses offered each year, many participants plan to return in 2018 and beyond. Next summer HILT will be hosted at the University of Pennsylvania from June 4-8, 2018. For updates on future learning opportunities, follow the HILT Twitter:@HILT_DH.
HILT Participants traveled across the continent to attend the institute. See a Carto map of participant locations here: HILT Participant Map.
More photos from HILT:
Article contributed by Jenifer Flaxbart and Hannah Packard.